
🛴 Simplifying the GraphQL data model
I wrote my second article for the LogRocket Blog, where I explain my journey on conceptualizing, designing and implementing a GraphQL server, as I have done for GraphQL by PoP:
“Don't think in graphs, think in components: Simplifying the GraphQL data model”
This article describes how the GraphQL server can use components as the data structure to represent the information (instead of using either graphs or trees), which has these benefits:
- It is easy to implement
- It is fast
For instance, let's say we have the following GraphQL query:
{
featuredDirector {
name
country
avatar
films {
title
thumbnail
actors {
name
avatar
}
}
}
}Using a graph, the data structure we must handle to solve the query is the following one:
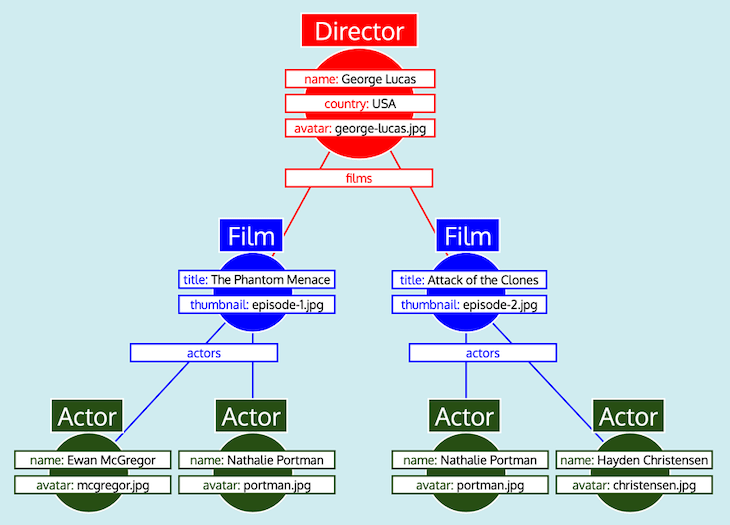
My strategy is, instead, to place the different components in a queue, one component per type and ordered from top to bottom in the graph (i.e. traversing from root to leaves), and then these can be processed in iterations:
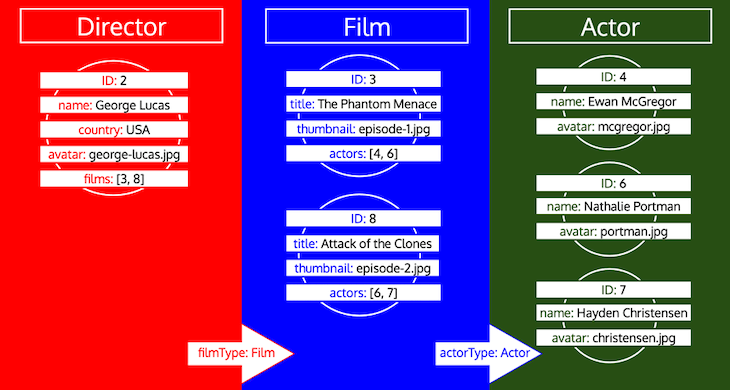
Using a queue, the number of queries executed against the database to fetch data grows linearly on the number of types involved in the query. In other words, its big O notation is O(n), where n is the number of types involved in the query. This performance is much better than using graphs or trees, which, if not handled properly, could have an exponential or logarithmic time complexity (meaning that a graph a few levels deep may become extremely slow to resolve).
Hence, this approach is simple and fast. I explain fully how and why this strategy works in my article for LogRocket.
This is an ongoing series, and coming soon will be more article on the different strategies employed to tackle all different concerns: decentralization, federation, security, and others.
Enjoy!