v1.0.
Yayyyyyyyyy!!!!!!
Check it out under its new home, gatographql.com.
![]()
v1.0.
Yayyyyyyyyy!!!!!!
Check it out under its new home, gatographql.com.
![]()

I noticed because, as I woke up on Sunday morning and I checked my traffic, I saw a wonderful spike:

By the end of the day, that blog post had brought in near 800 visitors (and they kept arriving the following day):

I believe this is the first time I reach the top of Google, when searching for some rather generic terms (say, without mentioning my name as part of the search).
I must admit, making it to the top of Google feels good!

Ok, so this is how it happened.
On Saturday, I wrote the blog post 🛠 Should WordPress have a GraphQL API in core? for my plugin's blog.
I had the blog post's URL, why-wordpress-should-have-a-graphql-api-in-core, contains those keywords I wanted the post to be associated with:
I then promoted the post on Reddit's /r/php channel, and shared it on Hacker News.
For HN, I posted it under the special section "Show HN", because the number of articles submitted there is lower, hence each post remains visible longer (before falling out of the first 30 results shown on the page).
The traffic on the "new" section is low, but really high on the front page. Then, the intention is to get the article upvoted, so it will make it to the Hacker News' front page (at least the one for Show HN).
A way to improve one's chances is to use a compelling title. Then, instead of using the blog post's actual title ("Should WordPress have a GraphQL API in core?"), I chose one more suitable to the Show HN ethos: "GraphQL API in WordPress core would look like this".
I crossed my fingers that the article would get upvoted, and went to sleep.
I woke up, and saw to my delight that the article got upvoted, and it made it to Show HN's front page. Yay!
I wish I had taken a screenshot. I did not. But it looked like this:

Google (I believe) picked it up from there, and the traffic then went through the roof 🚀

I was lucky this time, because people upvoting my article is out of my control. However, this is part of a long-term strategy, to have my plugin the GraphQL API for WordPress feature higher on Google.
That search result is actually a bit esoteric: "wordpress core graphql". Who adds the word "core"?
This is a step in between. The actual objective is to feature higher when searching for "wordpress graphql". And in this concern, my plugin is not doing great yet, but it's been improving!
When Googling "wordpress graphql", my plugin now shows on the homepage! (This was not the case as far as last week). It shows on the 7th position and, in addition, the 4th and 6th positions also concern my plugin:

WPGraphQL is currently dominating results for this search, taking positions 1, 2 and 3, which are the ones that truly matter.
But I'm coming behind, and will battle my way up 😜

It took so long, because when you're doing everything on your own (which is my case, I don't have a team), you literally need to do everything. So to make this website, I had to learn so many things:
And I even had to design the logo (with help from my wife):
![]()
It looks not bad, right? 😅
And all of that while still developing the plugin, and writing documentation, so that users can start playing with it immediately.
But it's been worth it. I'm very pleased with how it looks. Check this image for instance, added to the homepage:

I believe it's able to convey how powerful the product is, which was my goal all along.
Now, on to the next challenge: how to get people to visit it 🙀
]]>I released version 0.7 of the GraphQL API for WordPress, supporting mutations, and nested mutations! 🎉

Here is a tour showing the new additions.
GraphQL mutations enable to modify data (i.e. perform side-effect) through the query.
Mutations was the big item still missing from the GraphQL API. Now that it's been added, I can claim that this GraphQL server is pretty much feature-complete (only subscriptions are missing, and I'm already thinking on how to add them).

Let's check an example on adding a comment. But first, we need to execute another mutation to log you in, so you can add comments. Press the "Run" button on the GraphiQL client below, to execute mutation field loginUser with a pre-created testing user:
[🔗 Open GraphiQL client in new window]
Now, let's add some comments. Press the Run button below, to add a comment to some post by executing mutation field addCommentToCustomPost (you can also edit the comment text):
[🔗 Open GraphiQL client in new window]
In this first release, the plugin ships with the following mutations:
✅ createPost
✅ updatePost
✅ setFeaturedImageforCustomPost
✅ removeFeaturedImageforCustomPost
✅ addCommentToCustomPost
✅ replyComment
✅ loginUser
✅ logoutUser
Nested mutations is the ability to perform mutations on a type other than the root type in GraphQL.
They have been requested for the GraphQL spec but not yet approved (and may never will), hence GraphQL API adds support for them as an opt-in feature, via the Nested Mutations module.
Then, the plugin supports the 2 behaviors:
For instance, the query from above can also be executed with the following query, in which we first retrieve the post via Root.post, and only then add a comment to it via Post.addComment:
[🔗 Open GraphiQL client in new window]
Mutations can also modify data on the result from another mutation. In the query below, we first obtain the post through Root.post, then execute mutation Post.addComment on it and obtain the created comment object, and finally execute mutation Comment.reply on it:
[🔗 Open GraphiQL client in new window]
This is certainly useful! 😍 (The alternative method to produce this same behavior, in a single query, is via the @export directive... I'll compare both of them in an upcoming blog post).
In this first release, the plugin ships with the following mutations:
✅ CustomPost.update
✅ CustomPost.setFeaturedImage
✅ CustomPost.removeFeaturedImage
✅ CustomPost.addComment
✅ Comment.reply
You may have a GraphQL API that is used by your own application, and is also publicly available for your clients. You may want to enable nested mutations but only for your own application, not for your clients because this is a non-standard feature.
Good news: you can.
I've added a "Mutation Scheme" section in the Schema Configuration, which is used to customize the schema for Custom Endpoints and Persisted Queries:
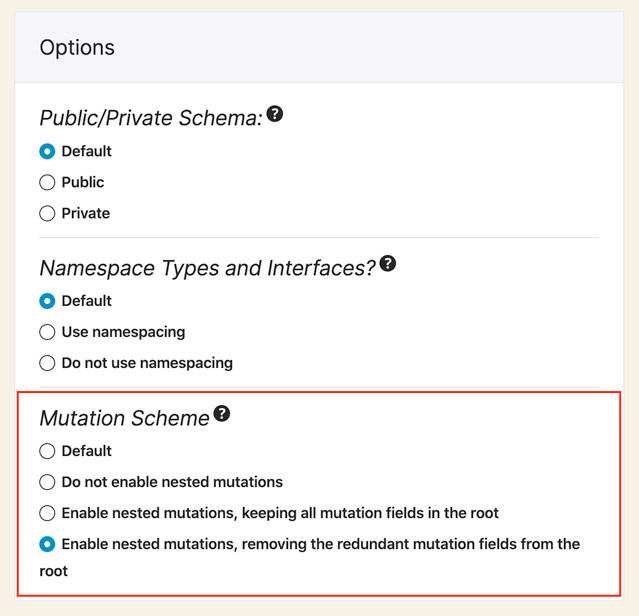
Hence, you can disable the nested mutations everywhere, but enable them just for a specific custom endpoint that only your application will use. 💪
With nested mutations, mutation fields may be added two times to the schema:
For instance, these fields can be considered a "duplicate" of each other:
Root.updatePostPost.updateThe GraphQL API enables to keep both of them, or remove the ones from the root type, which are redundant.
Check-out the following 3 schemas:
QueryRoot to handle queries and MutationRoot to handle queriesRoot type handles queries and mutations, and redundant mutation fields in this type are keptRoot type✱ Btw1, these 3 schemas all use the same endpoint, but changing a URL param ?mutation_scheme to values standard, nested and lean_nested. That's possible because the GraphQL server follows the code-first approach. 🤟
✱ Btw2, these options can be selected on the "Mutation Scheme" section in the Schema configuration (shown above), hence you can also decide what behavior to apply for individual custom endpoints and persisted queries. 👏
Check out the GraphQL API for WordPress, and download it from here.
Now it's time to start preparing for v0.8!
🙏
]]>Coding in PHP 7.4 and deploying to 7.1 via Rector and GitHub Actions
It explains all the hows and whys:
Enjoy!
]]>👉 What is the most effective way to reuse code, within a (single or multi-block) WordPress plugin?
The answer is here:
Reusing Functionality for WordPress Plugins with Blocks
Enjoy!
]]>I've learnt about Caleb Porzio's sponsorware model as a way to fund an open source project. The idea is to release a new feature only to the funders and, once you got X new funders, only then the new feature becomes open source, available to everyone.
But I haven't seen much success with this strategy yet to fund my open source plugin. The reason is clear: Sponsorware initially worked for Caleb because he asked the 10.000 subscribers on his newsletter for support, from which 75 agreed to be part of it. But I do not have 10.000 subscribers or followers or users, and building such a list takes time.
Caleb's second strategy seems much more promising: He also started selling access to tutorials on using the software. He says this strategy has been incredibly successful: as I'm writing this, he's surpassed 1100 sponsors!
The quest for learning appears to be a strong motivator to fund a project.
I've been delaying implementing this strategy, though, because it takes effort to:
The day has only 24 hs, and I'm working alone on my project, so there's only so much I can do. I've so far decided to prioritize improving the plugin first, adding all the minimal basic features that I would love to have as a user, and only then start producing tutorial videos.
I've actually been lucky: just a few days ago, site spatie.be (based on Laravel) was open sourced, making available the code implementing several of the required features:
So building the site is now within my reach. I just need to work on creating the videos.
Hopefully I'll soon be able to comment if selling tutorial videos can succeed in funding the open source plugin.
]]>Since I like owing my own content, I reproduce it here in my own blog.
I think Matt’s brutal honesty is welcome, because most information out there about the Jamstack praises it. However, it also comes from developers using these modern new tools, evaluating their own convenience and satisfaction. As Matt points out, that doesn’t mean it makes it easier for the end user to use the software, which is what WordPress is good at.
I actually like the Jamstack, but because of how complex it is, it’s rather limiting, even to support some otherwise basic functionality.
The definitive example is comments, which should be at the core websites building communities. WordPress is extremely good at supporting comments in the site. The Jamstack is sooooo bad at it. In all these many years, nobody has been able to solve comments for the Jamstack, which for me evidences that it is inherently unsuitable to support this feature.
All attempts so far have been workarounds, not solutions. Eg:
Also, all these solutions are overtly complicated. Do I need to set-up a webhook to trigger a new build just to add a comment? And then, maybe cache the new comment in the client’s LocalStorage for if the user refreshes the page immediately, before the new build is finished? Seriously?
And then, they don’t provide the killer feature: to send notifications of the new comment to all parties involved in the discussion. That’s how communities get built, and websites become successful. Speed is a factor. But more important than speed, it is dynamic functionality to support communities. The website may look fancy, but it may well become a ghost town.
(Btw, as an exercise, you can research which websites started as WordPress and then migrated to the Jamstack, and check how many comments they had then vs now… the numbers will, most likely, be waaaaaaay down)
Another way is to not pre-render the comments, but render them dynamically after fetching it with an API. Yes, this solution works, but then you still have WordPress (or some other CMS) in the back-end to store the comments :P
The final option is to use 3rd parties such as Disqus to handle this functionality for you. Then, I will be sharing my users’ data with the 3rd party, and they may use it who knows how, and for the benefit of who (most likely, not my users’). Since I care about privacy, that’s a big no for me.
As a result, my own blog, which is a Jamstack site, doesn’t support comments! What do I do if I want feedback on a blog post? I add a link to a corresponding tweet, asking to add a comment there. I myself feel ashamed at this compromise, but given my site’s stack, I don’t see how I can solve it.
I still like my blog as a Jamstack, though, because it’s fast, it’s free, and I create all the blog posts in Markdown using VSCode. But I can’t create a community! So, as Matt says, there are things the Jamstack can handle. But certainly not everything. And possibly, not the one(s) that enable your your website to become successful.
]]>
This is the second sponsor that I get, and the first one at the u$d 1400/m tier (the other was is at u$d 70/m).
This is a huge step forward, since it gives me the economic certainty as to keep developing the plugin (at least for the short/medium term... I still need a few more sponsors for it to become a living wage and long-term economic reliability).
I'll describe how it happened.
Several weeks ago, there was a proposal to introduce a fixed schedule to WordPress to bump the minimum required PHP version. Among the comments, one of them struck me:
So effectively this means that we cannot use PHP 8 syntax in themes/plugins if we want to support all WordPress versions until December 2023, 3 years after it has been released. This is very disappointing.
I work with WordPress. My plugin is for WordPress. Not being able to use the latest PHP features in 3 more years feels very disempowering.
So I decided to look for some solution, and I discovered Rector, a tool to reconstruct PHP code based on rules. It is like Babel, but for PHP. I asked if I could use Rector to transpile code from PHP 7.4 to 7.1, and they said yes, it could be done, but the rules to do it had not been created yet.
So I created them.
I contributed to this open source project full time for some 2 weeks, and produced some 15 rules to downgrade code, which I have applied to my plugin: Now I can code it using features from PHP 7.4 (and even from PHP 8.0), and release it to run on PHP 7.1, so it can still target most of the WordPress user base (only users running PHP 5.6 and 7.0 are out). That's a huge win!
After implementing those 15 rules, I documented the remaining rules to downgrade PHP code, and called it a day. I didn't mind working on them, but I didn't have the time to do it. Nevertheless, I also created this task as a sponsorable feature for my plugin; if anyone sponsored my time to work on it, I could then attempt to finish the task.
Well, Tomáš Votruba, creator of Rector, liked my contributions so he decided to become my sponsor.
Yay! 🍾 🎉 🎊 🥳 🍻 🥂
In exchange, I'll work on the downgrade rules, and even attempt to have Rector itself run on PHP 7.1.
Now, let's be clear: Tomáš is sponsoring me to work on Rector, not on GraphQL API for WordPress. That's why the sponsoring tier is u$d 1400/m, since it involves me working on the sponsor's repo.
While I get to increase the price for the tier, it makes no difference to me if the code is in my repo or my sponsor's: when I first worked those 2 weeks, it was for the benefit of my own plugin anyway, even if the code does not belong to my project.
Ultimately, where the code lives is not really important. What is important is that my project (and, for that matter, any project based on PHP) will be able to benefit from it.
In addition, anyone from the PHP community who starts using Rector because of my work on it, may learn that it was the GraphQL API for WP that made it possible, so I gain face and recognition.
So I think this is a win-win-win for all parties involved:
Some personal takeaways from this experience:
My next step is to share my work on Rector with the broader WordPress and PHP communities: I've just published an intro to downgrading from PHP 8.0 to 7.x, and in a few weeks I'll publish a step-by-step guide on transpiling code for a WordPress plugin, using my repo as the example.
Hopefully, along the way I'll be able to get new sponsors, and eventually achieve long-term economic certainty with my plugin 😀
]]>My presentation starts at 25:37. It is only around 20 min long (15 min presenting + 5 min of Q&A).
Please check it out. It's a succinct summary of the benefits of using GraphQL in WordPress, through my plugin GraphQL API for WordPress.
These are the slides:
I hope you enjoy it!
]]>My proposed feature then appears to be not about GraphQL as we know it nowadays, but about an über GraphQL, or what GraphQL could possibly be. That's either a problem, or an opportunity. In this write-up, Alan Johnson says:
[...] the execution model of GraphQL is in many ways just like a scripting language interpreter. The limitations of its model are strategic, to keep the technology focused on client-server interaction. What's interesting is that you as a developer provide nearly all of the definition of what operations exist, what they mean, and how they compose. For this reason, I consider GraphQL to be a meta-scripting language, or, in other words, a toolkit for building scripting languages.
I agree with this observation, but then I wonder: Where do these limitations start? What should be allowed, and what not? If any feature made GraphQL's scripting capabilities a bit more visible, gave a bit more control to the developer, and made the query a bit more powerful, should that be straightforward rejected? Or could it be given a chance?
Let's talk business now. Here is something that GraphQL is not good at.
Say that you have a @translate directive that is applied on a String, as in this query:
{
posts {
id
title @translate(from: "en", to: "es")
}
}You cannot apply @translate on a field different than a String. If you need to, you must then create a new directive, which involves extra effort (often being ad-hoc) and pollutes the schema:
If a field returns [String], you'd need to create another directive @translateArrays
If only some entries from the array must be translated, you need to add an optional argument $keys: [String] to specify which keys to translate
If the keys are not strings, but are numeric, you need another argument $numericKeys: [Int] as to avoid type conflicts
If instead of an array, you get an array of arrays, you need yet another directive
And so on, concerning any random requirement from your clients.
As a result, the schema might eventually become unwieldy.
So, how could this situation be improved for GraphQL?
If GraphQL had capabilities to compose or manipulate fields, then a few elements could already satisfy all possible combinations.
GraphQL by PoP (the engine powering the recently launched GraphQL API for WordPress) is a GraphQL server because it respects the GraphQL spec, but is also a non-standard API server that provides other capabilities, including composable fields and composable directives.
Let's see how this server can satisfy all combinations described above, with just a few elements:
Notes:
- GraphQL by PoP relies on the URL-based PQL syntax, so you can click on the links to execute the query and see its response
- Field
Root.echois used to build the arraysforEachandadvancePointerInArrayare directives that composes another directive
Translating posts as strings (run query):
posts.title<
translate(from:en, to:es)
>Translating a list of strings (run query):
echo([
hello,
world,
how are you today?
])<
forEach<
translate(from:en,to:es)
>
>Translating only one element from the list of strings, with numeric keys (run query):
echo([
hello,
world,
how are you today?
])<
advancePointerInArray(path: 0)<
translate(from:en,to:es)
>
>Translating only one element from the list of strings, with keys as strings (run query):
echo([
first:hello,
second:world,
third:how are you today?
])<
advancePointerInArray(path:second)<
translate(from:en,to:es)
>
>Translating an array of arrays (run query):
echo([[
one,
two,
three
], [
four,
five,
six
], [
seven,
eight,
nine
]])<
forEach<
forEach<
translate(from:en,to:es)
>
>
>And so on, concerning any random requirement from your clients.
In my opinion, these features make the queries more powerful, and the schema more elegant. So they could be perfectly considered to be added to GraphQL.
Bringing these additional scripting capabilities to GraphQL, wouldn't it be more valuable than not?
I understand that there is more complexity added to the server. But that's a one-time off. The GraphQL server maintainers can implement these features in a few months, and developers would be able to use them forever.
Isn't that a good tradeoff?
]]>If we want to make GraphQL good at transforming data, we need much more than string interpolation.
I don't disagree with this, but I don't have a clear answer. If we allow String interpolation, should we do the same for Ints, such as allowing additions or substractions?
I'd say no, but then why not? If we do allow it, something like this could be possible:
query {
service @include(if: {{ totalCredits }} - {{ usedCredits }} > 0) {
id
}
}I do not support this use case as shown here, I certainly don't like it. The question is why then we do allow for String interpolation? Because it enables templating, which could be considered a legitimate use case:
mutation {
comment(id: 1) {
replyToComment(data: data) {
id @sendEmail(
to: "{{ parentComment.author.email }}",
subject: "{{ author.name }} has replied to your comment",
content: "
<p>On {{ comment.date(format: \"d/m/Y\") }}, {{ author.name }} says:</p>
<blockquote>{{ comment.content }}</blockquote>
<p>Read online: {{ comment.url }}</p>
"
)
}
}
}Programming languages are good at transforming data. Why not use application logic?
Indeed, my initial proposed features for the spec, composable fields and composable directives, add meta-scripting capabilities to GraphQL.
How could that be benefitial? Say that you have a @translate directive that is applied on a String, as in this query:
query {
posts {
id
title @translate(from: "en", to: "es")
}
}Now, what happens if a field returns [String], i.e. a list of Strings? Then you can't use @translate anymore, you'd need to create another directive @translateArrays. And if there is only one entry from the array you need to translate, and not all of them? Then you need to add an optional argument $keys: [String] to specify which keys to translate. And if the keys are not strings, but are numeric? Or if instead of an array, you get an array of arrays? And so on, and on, and on.
Working with only fields to fetch data, the schema might eventually become unwieldy.
Now, if we have capabilities to compose or manipulate fields, then there is no need to pollute the schema with ad-hoc fields to satisfy each custom combination.
For GraphQL by PoP (a GraphQL server that I've designed from scratch), I have accomplished this through a syntax called PQL, which is a superset from the GraphQL query, supporting composable fields and composable directives.
Let's see how all combinations can be satisfied just composing elements:
posts.title<translate(from:en,to:es)>echo([hello, world, how are you today?])<forEach<translate(from:en,to:es)>>echo([hello, world, how are you today?])<advancePointerInArray(path: 0)<translate(from:en,to:es)>>echo([first:hello, second:world, third:how are you today?])<advancePointerInArray(path:second)<translate(from:en,to:es)>>echo([[one, two, three], [four, five, six], [seven, eight, nine]])<forEach<forEach<translate(from:en,to:es)>>>Embeddable fields is a watered-down version of composable fields, good enough for templating, but not for more advanced use cases.
In your article you argue, that it is better to do this on GraphQL, but I don't understand why it would be.
I think there is value in GraphQL having additional capabilities. If a GraphQL query can execute a complex operation all by itself, the query may become more difficult, but the overall application would become much simpler.
For instance, instead of a typical workflow of using GraphQL to retrieve data, process the data in the client with JavaScript, and then execute some operation in the server with this data, a single GraphQL query with meta-scripting capabilities can completely do away with the client. This is not just fewer lines of code, it's also fewer systems involved.
As an example that I've implemented for demonstration purposes, a single query can send a localized newsletter.
This is not far-fetched. I think GraphQL can be considered good for more than just fetching and posting data, because in this modern world of APIs interacting with cloud-based services, it's difficult to determine what is fetching data, and what is executing functionality.
For instance, are these cases within the confines of just fetching/posting data?
These are all operations that can be perfectly integrated within the GraphQL service, and that are typically found on a CI/CD pipeline. Imagine if the pipeline stages were GraphQL queries. GraphQL would then become the interface not just for fetching/posting data, but also for interacting with services.
I'm pretty confident that providing a robust support to GraphQL to interact with these cloud-based services can only make our API more powerful, capable of supporting more use cases, and better prepared for new requirements in the future.
Another principle for GraphQL was coined by Lee Byron: A GraphQL server should only expose queries, that it can fulfill efficiently.
These are not contradictory propositions. If well architected, the GraphQL server will not necessarily degrade its performance. GraphQL by PoP, for instance, resolves the query with linear complexity time on the number of types, so it supports composable fields to any number of levels without a scratch.
The more features we add to GraphQL, the harder it becomes to ensure, that the queries are efficiently executable.
Same as above.
Furthermore, your functionality requires consecutive resolver executions for one single field. This fundamentally changes how queries are executed (in a way that IMO is incompatible with the spec).
That's up to interpretation. I have not seen it described in the spec, and I believe it should not be there, since the spec is about defining standards on how the API must behave, and not about the nitty-gritty of the server's implementation.
GraphQL is designed to be simple on purpose.
I agree that these changes add complexity to the GraphQL servers, and extra capabilities to the GraphQL queries that make it more difficult to learn.
But at the same time, they make the GraphQL service more powerful and versatile, and enable the architecture of the overall application to become simpler.
For me the question is, is it worth it?
]]>This post is part of the groundwork to find out if there is support for this feature within the GraphQL community. If there is, only then I'll submit it as a new issue to the GraphQL spec repo for a thorough discussion, and offer to become its champion.
Note: This feature is already supported by GraphQL by PoP. Click on the "Run" button on the GraphiQL clients throughout this post, to execute the query and see the expected response.
Embeddable fields is a syntax construct, that enables to resolve a field within an argument for another field from the same type, using the mustache syntax {{field}}.
Note: To make it convenient to use, field
echoStr(value: String): Stringcan be added to the schema, as in the examples shown throughout this post.
This query contains embedded fields {{title}} and {{date}}:
The syntax can contain whitespaces around the field: {{ field }}.
This query contains embedded fields {{ title }} and {{ date }}:
The embedded field may or may not contain arguments:
{{ fieldName }}{{ fieldName(fieldArgs) }}This query formats the date: date(format: \"d/m/Y\"):
Note: The string quotes must be escaped:
\"
Embedded fields also work within directive arguments.
This query resolves field title only if the same post has comments:
Note: Using embeddable fields together with directives
@skipand@includeis an interesting use case. However, conditionifexpects aBoolean, not aString; even though the query can be resolved properly in the server, there is type mismatch in the client.This proposal may suggest to accept embedded fields also on their own, and not only within a string, so they can be casted to their own type:
@skip(if: {{ hasComments }}). More on this below.
This query resolves field title in two different ways, depending on the post having comments or not:
Why would we want a GraphQL query to support embeddable fields? The following are benefits I've identified so far.
In most situations, we have a client to request the data from the GraphQL server and transform it into the required format.
For instance, a website on the client-side can process the data with JavaScript, as to transform fields title and date into a description:
const desc = `Post ${ response.data.title } was published on ${ response.data.date }`However, in some situations we may need to retrieve the data for a service that we do not control, and which does not offer tools to process the results.
For instance, a newsletter service (such as Mailchimp) may accept to define an endpoint from which to retrieve the data for the newsletter. Whatever data is returned by the endpoint is final; it can't be manipulated before being injected into the newsletter.
In these situtations, the query could use embeddable fields to manipulate the response into the required format. This could be particularly useful when accessing GraphQL over HTTP.
The use case above could also be satisfied by adding an extra field Post.descriptionForNewsletter to the schema. But this solution clutters the schema, and embeddable fields could be considered a more elegant solution.
Embeddable fields could be compared to arrow functions in JavaScript, which is syntactic sugar over a feature already available in the language.
Arrow functions are not really needed, but they provide benefits:
As such, the feature becomes a welcome-to-have in the language, producing a better development experience.
if condition in @skip and @include can become dynamicCurrently, argument "if" for the @skip and @include directives can only be an actual boolean value (true or false) or a variable with the boolean value. This behavior is pretty static.
Embeddable fields would enable to make this behavior more dynamic, by evaluating the condition on some property from the object itself.
There is an issue to address: if is a Boolean, not a String, so to avoid type conflicts the GraphQL syntax may also need to accept the embedded field on its own, not wrapping it between string quotes:
query {
posts {
id
title @skip(if: {{ hasComments }})
}
}Removing the need to wrap {{ }} between quotes " " would solve this issue for every scalar type other than String, not just Boolean (check the example below with droid, using embeddable fields to resolve an ID).
Embeddable fields enable to embed a template within the GraphQL query itself, which would render the GraphQL service more configuration-friendly.
For instance, combined with the flat chain syntax and nested mutations (two other features also proposed for the spec), we could produce the following query, which sends an email to the user notifying that his/her comment was replied to:
mutation {
comment(id: 1) {
replyToComment(data: data) {
id @sendEmail(
to: "{{ parentComment.author.email }}",
subject: "{{ author.name }} has replied to your comment",
content: "
<p>On {{ comment.date(format: \"d/m/Y\") }}, {{ author.name }} says:</p>
<blockquote>{{ comment.content }}</blockquote>
<p>Read online: {{ comment.url }}</p>
"
)
}
}
}Proposed feature [RFC] exporting variables between queries attempts to @export the value of a field, and inject it into another field in the same query:
query A {
hero {
id @export(as: "droidId")
}
}
query B($droidId: String!) {
droid (id: $droidId) {
name
}
}With embeddable fields and the flat chain syntax, this use case could be satisfied like this:
query {
droid (id: {{ hero.id }} ) {
name
}
}This feature breaks backwards compatibility. From the spec:
Once a query is written, it should always mean the same thing and return the same shaped result. Future changes should not change the meaning of existing schema or queries or in any other way cause an existing compliant GraphQL service to become non-compliant for prior versions of the spec.
In our case, if a query currently has this shape:
query {
foo: echoStr(value: "Hello {{ world }}!")
}...it expects the response to be:
{
"data": {
"foo": "Hello {{ world }}!"
}
}With embeddable fields the query above will produce a different response and, moreover, it may even produce an error message, as when there is no field Root.world.
In addition, considering the case of not wrapping {{ }} between string quotes " ", as in the query below:
query {
posts {
id
title @skip(if: {{ hasComments }})
}
}Currently, this query would produce a syntax error, being displayed in the GraphiQL client, and possibly not parsed by the server. This behavior would change.
Because of being backwards incompatible, it is suggested to make embeddable fields an opt-in feature, prompting users to be fully aware of the consequences before enabling it.
Embeddable fields would affect some components from the GraphQL workflow. How should these be dealt with?
The GraphiQL client shows an error message when a field does not exist, or if a field argument receives a value with a different type than declared in the schema, among other potential errors. Can this information be conveyed for embeddable fields too?
For this to happen, GraphiQL would need to parse the field argument inputs and identify all {{ fieldName(fieldArgs) }} instances, as to do the validations and show the error messages.
What happens when an embedded field does not exist? For instance, if in the query below, field {{ name }} exists but {{ surname }} does not:
{
users {
fullName: echoStr(value: "{{ name }} {{ surname }}")
}
}Should the response produce an error message, and skip processing the field? Eg:
{
"errors": [
"Field 'surname' does not exist, so 'echoStr(value: \"{{ name }} {{ surname }}\")' cannot be resolved"
]
}Or should the missing field be skipped but still resolve the field, and possibly show a warning? Eg:
{
"warnings": [
"Field 'surname' does not exist"
],
"data": {
"users": [
{
"fullName": "Juan {{ surname }}"
},
{
"fullName": "Pedro {{ surname }}"
},
{
"fullName": "Manuel {{ surname }}"
}
]
}
}Or should the failing field be removed altogether? (Notice there's still a space at the end of each resolved value):
{
"warnings": [
"Field 'surname' does not exist"
],
"data": {
"users": [
{
"fullName": "Juan "
},
{
"fullName": "Pedro "
},
{
"fullName": "Manuel "
}
]
}
}{{ field }}If we actually want to print the string "{{ field }}" in the response, without resolving it, how should it be done?
This feature is a less ambitious version of composable fields, differing in these aspects:
Embeddable fields are supported in GraphQL server GraphQL by PoP, and its implementation for WordPress GraphQL API for WordPress, in both as an opt-in feature.
If there is enough support for this feature, I will add an RFC issue to the GraphQL spec. Everyone is welcome to provide feedback in this Reddit post:
This is a mighty new version, with several new features and improvements:
✅ The GraphiQL Explorer has been added to all the GraphiQL clients, including the public ones ✅ Added support for GitHub Updater, to enable self-updating when there's a new version ✅ The plugin is coded with PHP 7.4, and can run with PHP 7.1 ✅ Introduced "embeddable fields", a custom GraphQL query syntax construct to enable templating and improve performance ✅ PHPStan has been upgraded to level 8 (the strictest level), reducing the change of bugs happening ✅ Release notes are displayed within the plugin, after being updated
👉🏽 Read the descriptions in detail in the release notes.
👉🏽 Install the plugin in your site: download gatographql.zip, and in the wp-admin go to Plugins => Add New => Upload Plugin to install it.
mutation {
comment(id: 1) {
replyToComment(data: data) {
id @sendEmail(
to: "{{ parentComment.author.email }}",
subject: "{{ author.name }} has replied to your comment",
content: "
<p>On {{ comment.date(format: \"d/m/Y\") }}, {{ author.name }} says:</p>
<blockquote>{{ comment.content }}</blockquote>
<p>Read online: {{ comment.url }}</p>
"
)
}
}
}This query demonstrates how sending notifications via Symfony Notifier will be accomplished (for email, Slack and SMS). It makes use of a few pioneering features, still being considered (to more or less extent) for the GraphQL spec:
🔥 Nested mutations
🔥 Embeddable fields (based on composable fields)
🔥 Flat chain syntax
I am working to get the funding to implement them, through my recently launched GitHub sponsors. In total, currently there are 23 features looking for sponsorship:
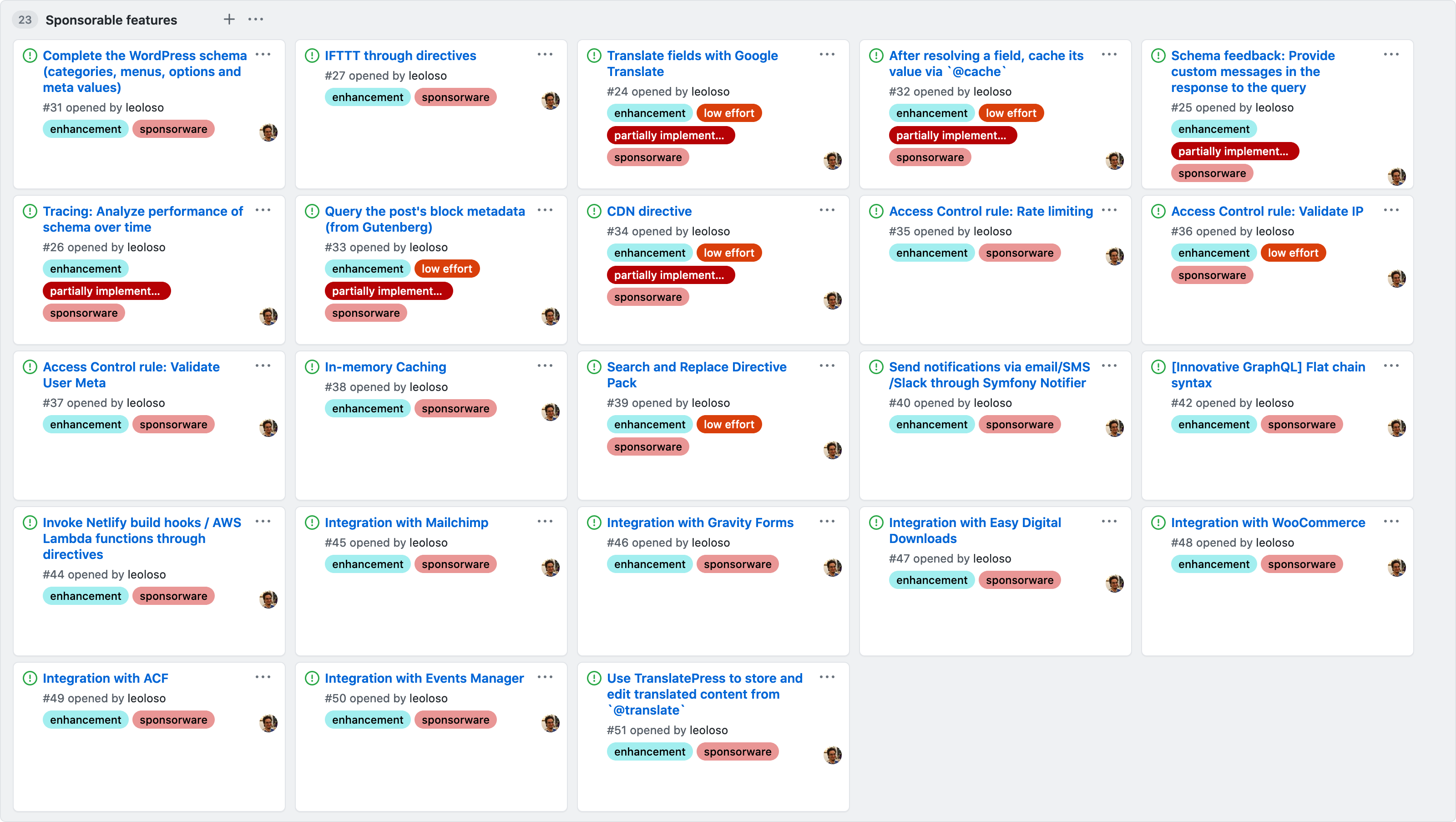
Once implemented, the GraphQL API for WordPress may perfectly be the most forward-looking GraphQL in the market 🙀.
What do you think? Is it worth sponsoring this project? Want to become a sponsor?
Please share with your friends and colleagues! 🙏
]]>I'm building (I hope) the most forward-looking GraphQL server out there.
— Leonardo Losoviz (@losoviz) September 14, 2020
Here is how I plan to make it happen.https://t.co/2lOvqqh4lM

Following the example set by Caleb Porzio (who's making more than u$d 100k/y doing open source), I have decided to use the sponsorware model to fund my project. It works like this:

In a few months, I will also start creating instructional videos, explaining how to make the most out of the plugin. According to Caleb, this is the biggest money-making strategy.
I have also decided to add a middle tier (at u$d 70/m), where I provide Slack-based personal support, to help users of my plugin set-up GraphQL with WordPress, troubleshooting, and answering their questions. A user needed help to develop a functionality, so he decided to sponsor me <= my first sponsor ❤️
Finally, I added a higher tier (at u$d 700) for corporate sponsors. I plan to ask around in the WordPress community if their companies may be interested in participating. That would be a win-win: They get plenty of face from contributing to open source, and I get the certainty that I can make a living wage from my work and can focus on the development of the plugin (and not on marketing, which is not my forte).

I hope the sponsorware model works, and I can make a living while working on open source. I'll keep writing updates on how it goes, here on my blog, and on IndieHackers.
I have now listed down all the features I plan to implement if I can get the funding. Right now, there are 23 of them (some of them are low-effort, so they can be bundled together):
Adding directives to the schema in code-first GraphQL servers
This time, I explore several topics:
Now that the GraphQL API for WordPress has been released, I can use it to demonstrate the IFTTT feature, to add directives to the schema by configuration, not code:

As always, I hope you enjoy it!
]]>But, surprise surprise, they had not deleted my photos! For instance, this photo of mine was still hosted in their cloud:

These guys should have deleted all my data, absolutely all of it, including photos. To be sure that that would happen, I explicitly mentioned this when requesting to close down my account:

They deleted my account, and replied back saying that they were closing the ticket. As I noticed that my photos were still there, I replied to that same email, asking them, once again, to delete them:

To which I got a response, saying that my ticket would be handled within 3 days:

(Btw, if they deleted my data from their customer support tool, how does this system still know that my name is Leonardo? I hope they got it from the email headers, instead of lying about it.)
After one week, no response, my photos were still there. I wrote a new ticket to them:

And what was their response? That they needed 1 month to delete my photos!!!

I replied back, asking why deleting a folder from AWS S3 (the hosting service from Amazon) takes such a long time:

I use AWS myself, and I know what it takes: Login to AWS => Click on the S3 link => Browse to the folder => Delete all the images => Delete the folder. Amount of time required: 5 minutes. 15 minutes max.
I got their response, saying they were escalating this issue:

But, surprise surprise, they never contacted me again! And even more, 2 weeks later I got an automatic response, saying that my ticket was being closed because they hadn't heard back from me!:

I had to reply again, just to keep the ticket open:

And then I got a new response: they still needed 2 weeks to "manually" process my request:

That was the last interaction with them. These 2 weeks, I kept checking if my photos were there. Just before the 2 weeks were over, the photos had been deleted.
Escalation? What escalation? They took their whole time. Giving me a response after they had deleted my photos? Nops, that never happened. How did Zendesk know my name? They never explained. What other data do they still have about me? Who knows?
The main issue is: why did they have to manually delete my photos? When I requested to have my data deleted, that meant all my data, including the photos. If they have some automatic system to delete data, they seem to be cherry-picking what data to delete.
I had to write not once but twice, to have my data actually deleted, and wait and wait and wait.
My wife also wrote to them, twice, to have her photos deleted. But they never replied back to her, and up to this day her photos are still in their cloud.
I know what will happen. If they come across this blog post, the Couchsurfing guys will make some excuse, they will say it was a mistake, "we are very sorry, but look, we have deleted the images now, and we'll take better care in the future, because we care about our community, oh yes we love our community" (and then they'll repeat the word community 37 times).
I wouldn't be surprised that this is not an isolated case (and my wife's photos are still hosted by them, after she repeatedly requested for their deletion). I bet that they are only deleting the user data from their website database, but they are keeping some other assets, such as the user photos.
And this, through the GDPR legislation, is illegal.
I'm not European, so I can't do anything about it. But if you're European, and you have requested to delete your CS account and all its data, you can try to find out if they have deleted your images!.
If they still hold your photos (which is your data, not theirs), they could be punished through GDPR.
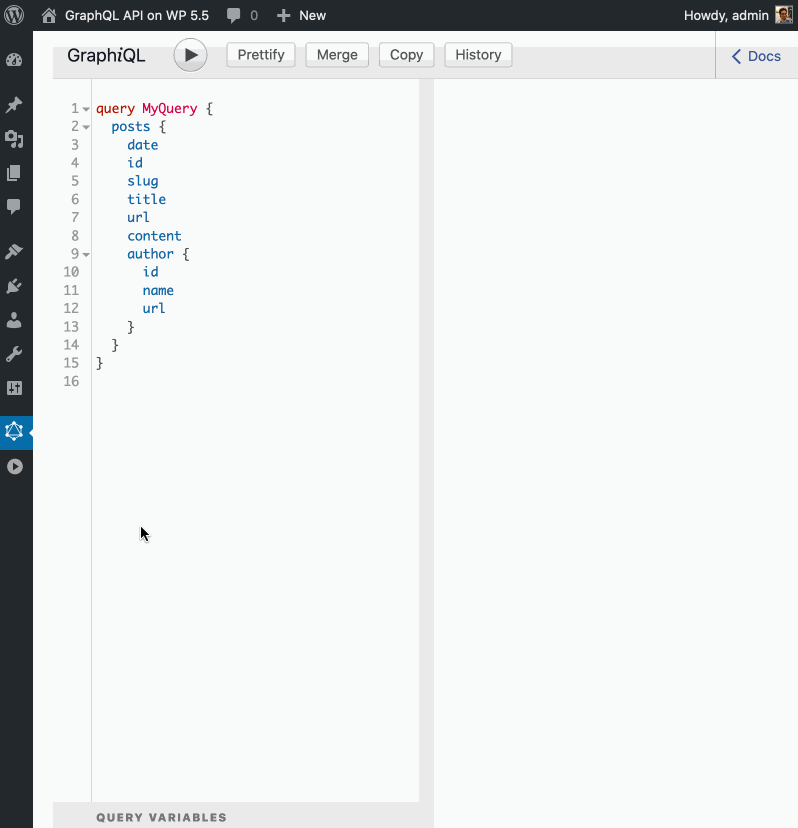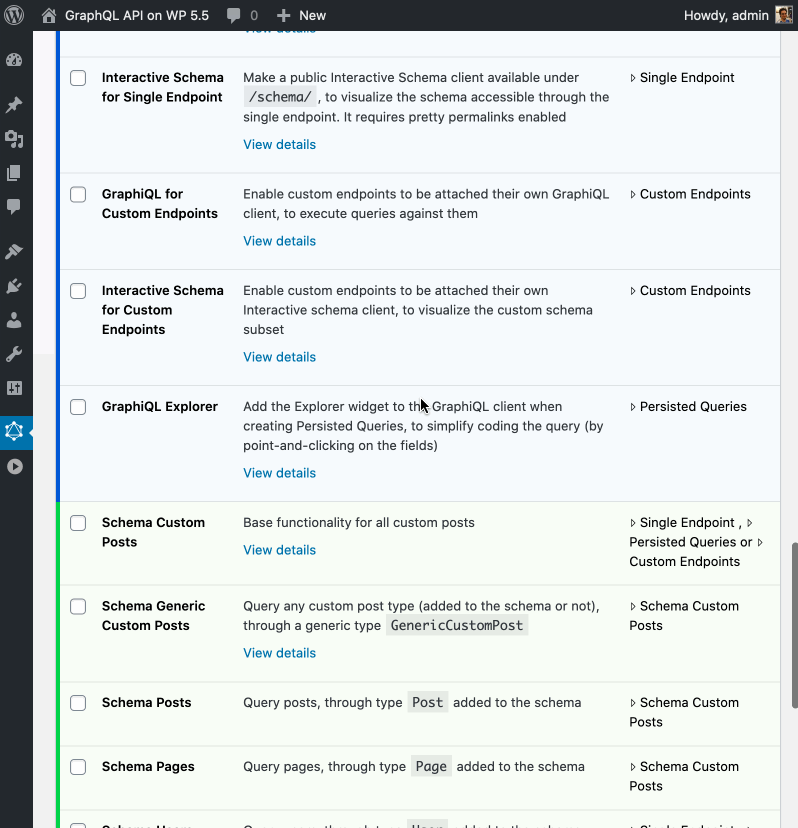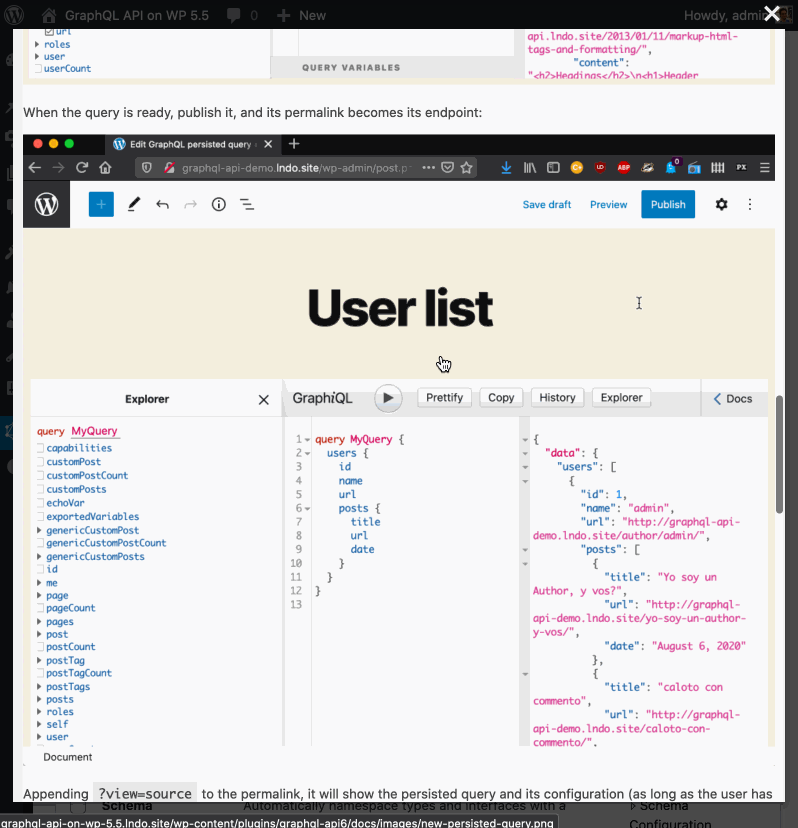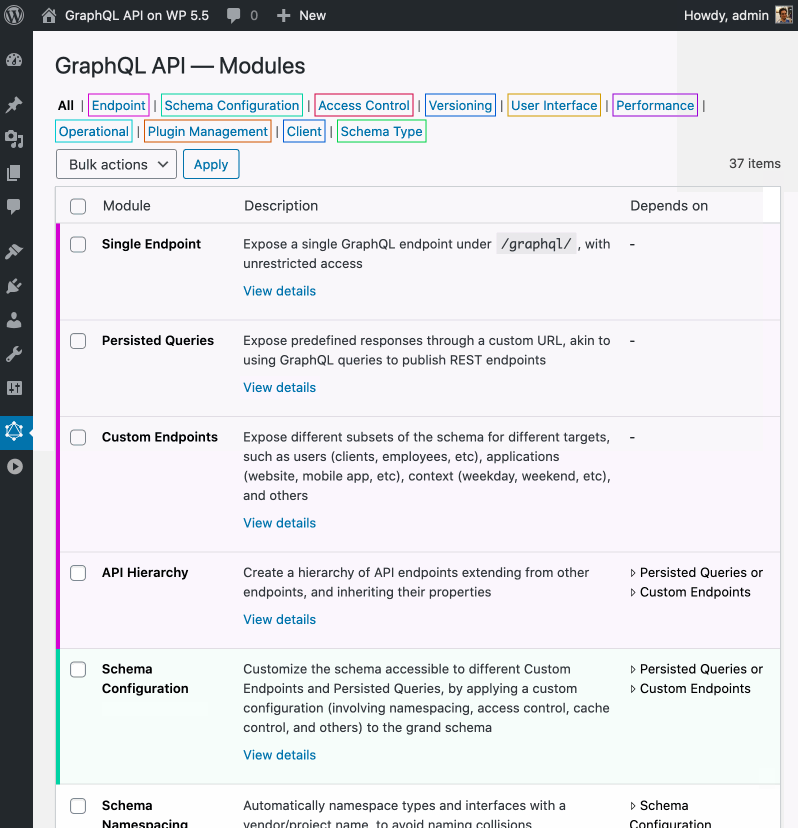
]]>The plugin now ships 37 modules from 10 categories, distinguished by color:

The docs have been implemented as Markdown, and they are opened when clicking on the View details link below each module:
Since Markdown can also be viewed directly in the GitHub repo, I implemented a cool feature: the same docs can be viewed within the plugin, or in the repo, from a single source of truth, but with 2 different presentations:
Check out the doc for Persisted Queries in the repo, and the same doc in the plugin:
Cool, isn't it? 😎
If you want to find out how it's done, the implementation code is here.
]]>It's been only 15 days since releasing the GraphQL API for WordPress, and I couldn't help myself, so this week I added yet a new feature: the server can now execute multiple queries in a single operation.

This is not query batching. When doing query batching, the GraphQL server executes multiple queries in a single request. But those queries are still independent from each other. They just happen to be executed one after the other, to avoid the latency from multiple requests.
In this case, all queries are combined together, and executed as a single operation. That means that they will reuse their state and their data. For instance, if a first query fetches some data, and a second query also accesses the same data, this data is retrieved only once, not twice.
This feature is shipped together with the @export directive, which enables to have the results of a query injected as an input into another query. Check out the query below, hit "Run" and select query with name "__ALL", and see how the user's name obtained in the first query is used to search for posts in the second query:
(GraphiQL currently does not allow to execute multiple operations. Hence, that __ALL query is a hack I added, as to tell the GraphQL server to execute all queries.)
This functionality is currently not part of the GraphQL spec, but it has been requested:
This feature improves performance, for whenever we need to execute an operation against the GraphQL server, then wait for its response, and then use that result to perform another operation. By combining them together, we are saving this extra request.
You may think that saving a single roundtrip is no big deal. Maybe. But this is not limited to just 2 queries: it can be chained, containing as many operations as needed.
For instance, this simple example chains a third query, and adds a conditional logic applied on the result from a previous query: if the post has comments, translate the post's title to French, but if it doesn't, show the name of the user. Click on the "Run" button below, see the results, then change variable offset to 1, run the query again, and see how the results change:
As we've seen, we could attempt to use GraphQL to execute scripts, including conditional statements and even loops.
GraphQL by PoP, which is the GraphQL engine over which the GraphQL API for WordPress is based, is a few steps ahead in providing a language to manipulate the operations performed on the query graph.
For instance, I have implemented a query which allows to send a newsletter to multiple users, fetching the content of the latest blog post and translating it to each person's language, all in a single operation!
Check the query below, which is using the PoP Query Language, an alternative to the GraphQL Query Language:
/?
postId=1&
query=
post($postId)@post.
content|
date(d/m/Y)@date,
getJSON("https://newapi.getpop.org/wp-json/newsletter/v1/subscriptions")@userList|
arrayUnique(
extract(
getSelfProp(%self%, userList),
lang
)
)@userLangs|
extract(
getSelfProp(%self%, userList),
email
)@userEmails|
arrayFill(
getJSON(
sprintf(
"https://newapi.getpop.org/users/api/rest/?query=name|email%26emails[]=%s",
[arrayJoin(
getSelfProp(%self%, userEmails),
"%26emails[]="
)]
)
),
getSelfProp(%self%, userList),
email
)@userData;
post($postId)@post<
copyRelationalResults(
[content, date],
[postContent, postDate]
)
>;
getSelfProp(%self%, postContent)@postContent<
translate(
from: en,
to: arrayDiff([
getSelfProp(%self%, userLangs),
[en]
])
),
renameProperty(postContent-en)
>|
getSelfProp(%self%, userData)@userPostData<
forEach<
applyFunction(
function: arrayAddItem(
array: [],
value: ""
),
addArguments: [
key: postContent,
array: %value%,
value: getSelfProp(
%self%,
sprintf(
postContent-%s,
[extract(%value%, lang)]
)
)
]
),
applyFunction(
function: arrayAddItem(
array: [],
value: ""
),
addArguments: [
key: header,
array: %value%,
value: sprintf(
string: "<p>Hi %s, we published this post on %s, enjoy!</p>",
values: [
extract(%value%, name),
getSelfProp(%self%, postDate)
]
)
]
)
>
>;
getSelfProp(%self%, userPostData)@translatedUserPostProps<
forEach(
if: not(
equals(
extract(%value%, lang),
en
)
)
)<
advancePointerInArray(
path: header,
appendExpressions: [
toLang: extract(%value%, lang)
]
)<
translate(
from: en,
to: %toLang%,
oneLanguagePerField: true,
override: true
)
>
>
>;
getSelfProp(%self%,translatedUserPostProps)@emails<
forEach<
applyFunction(
function: arrayAddItem(
array: [],
value: []
),
addArguments: [
key: content,
array: %value%,
value: concat([
extract(%value%, header),
extract(%value%, postContent)
])
]
),
applyFunction(
function: arrayAddItem(
array: [],
value: []
),
addArguments: [
key: to,
array: %value%,
value: extract(%value%, email)
]
),
applyFunction(
function: arrayAddItem(
array: [],
value: []
),
addArguments: [
key: subject,
array: %value%,
value: "PoP API example :)"
]
),
sendByEmail
>
>(Please don't be shocked by this complex query! The PQL language is actually even simpler than GraphQL, as can be seen when put side-by-side.)
To run the query, there's no need for GraphiQL: it's URL-based, so it can be executed via GET, and a normal link will do. Click here and marvel: query to create, translate and send newsletter (this is a demo, so I'm just printing the content on screen, not actually sending it by email 😂).
What is going on there? The query is a series of operations executed in order, with each passing its results to the succeeding operations: fetching the list of emails from a REST endpoint, fetching the users from the database, obtaining their language, fetching the post content, translating the content to the language of each user, and finally sending the newsletter.
To check it out in detail, I've written a step-by-step description of how this query works.
You may think that you don't need to implement a newsletter-sending service. But that's not the point. The point is that, if you can implement this, you can implement pretty much anything you will ever need.
The query above uses a couple of features available in PQL but not in GQL, which I have requested for the GraphQL spec:
Sadly, I've been told that these features will most likely not be add to the spec.
Hence, GraphQL cannot implement the example, yet. But through executing multiple queries in a single operation, @export, and powerful custom directives, it can certainly support novel use cases.
vendor/, are not stored in the GitHub repo, because they do not belong there.
However, these dependencies must be inside the .zip file when installing the plugin in the WordPress site. Then, when and how do we add them into the release?
The answer is to create a GitHub action which, upon tagging the code, will automatically create the .zip file and upload it as a release asset.
The end result looks like this: In addition to the Source code (zip) (which does not contain the PHP dependencies), the release assets contain a gatographql.zip file, which does have the PHP dependencies, and is the actual plugin to install in the WordPress site:

In this post, I'll demonstrate step-by-step the GitHub action to build the plugin.
Before attempting to create my own action, I tried the following ones:
None of them worked for my case. Concerning 10up's action, its purpose is to upload the plugin release from GitHub to WordPress' SVN. This can be very useful, saving us plenty of time by avoiding to do this bureaucratic conversion manually. However, I can't use it, because my plugin is not in the WordPress plugin directory yet (for the time being, it's available only through GitHub). I attempted to use it just to generate the .zip file, without uploading to the SVN, but nope, it doesn't work.
upload-release-asset should have been suitable for my use case, however I couldn't make it work properly, because this action creates a release, which is then uploaded as an asset. However, when tagging the source code (say, with v0.1.5), the release is already created! Hence, this tool would create yet-another release, which is far from ideal. And even worse, it requires parameter tag_name, but this tag can't be the same used for tagging the source code, or it gives a duplicated error. Then, my source code was being tagged twice: first manually as v0.1.5, and then automatically as plugin-v0.1.5. Very far from ideal.
So, I created my own action.
The action is this one:
name: Generate Installable Plugin, and Upload as Release Asset
on:
release:
types: [published]
jobs:
build:
name: Upload Release Asset
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Build project
run: |
composer install --no-dev --optimize-autoloader
mkdir build
- name: Create artifact
uses: montudor/action-zip@v0.1.0
with:
args: zip -X -r build/gatographql.zip . -x *.git* node_modules/\* .* "*/\.*" CODE_OF_CONDUCT.md CONTRIBUTING.md ISSUE_TEMPLATE.md PULL_REQUEST_TEMPLATE.md *.dist composer.* dev-helpers** build**
- name: Upload artifact
uses: actions/upload-artifact@v2
with:
name: graphql-api
path: build/gatographql.zip
- name: Upload to release
uses: JasonEtco/upload-to-release@master
with:
args: build/gatographql.zip application/zip
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}The workflow is like this:
The action, called "Generate Installable Plugin, and Upload as Release Asset", is executed whenever a new release is created, i.e. whenever I tag my code, as defined in the on entry:
name: Generate Installable Plugin, and Upload as Release Asset
on:
release:
types: [published]The computer (called a "runner") where it runs is a Linux:
jobs:
build:
name: Upload Release Asset
runs-on: ubuntu-latestThe first step is to check out the source code from the repo:
steps:
- name: Checkout code
uses: actions/checkout@v2Then, it builds the WordPress plugin, by having Composer download the PHP dependencies and store them under vendor/. This is the crucial step, for which this action exists.
Because this is the plugin for production, we can attach options --no-dev --optimize-autoloader to optimize the release:
- name: Build project
run: |
composer install --no-dev --optimize-autoloaderNext, we will create the .zip file, stored under a build/ folder. We first create the folder:
mkdir buildAnd then make use of montudor/action-zip to zip the files into build/gatographql.zip.
In this step, I also exclude those files and folder which are needed when coding the plugin, but are not needed in the actual final plugin:
.git, .gitignore, etc)node_modules/ folder (there should be none, but just in case...)phpcs.xml.dist, phpstan.neon.dist and phpunit.xml.dist)composer.json and composer.lockCODE_OF_CONDUCT.md, CONTRIBUTING.md, ISSUE_TEMPLATE.md and PULL_REQUEST_TEMPLATE.mdbuild/, which is created only to store the .zip filedev-helpers/, which contains helpful scripts for development - name: Create artifact
uses: montudor/action-zip@v0.1.0
with:
args: zip -X -r build/gatographql.zip . -x *.git* node_modules/\* .* "*/\.*" CODE_OF_CONDUCT.md CONTRIBUTING.md ISSUE_TEMPLATE.md PULL_REQUEST_TEMPLATE.md *.dist composer.* dev-helpers** build**After this step, the release will have been created as build/gatographql.zip. Next, as an optional step, we upload it as an artifact to the action:
- name: Upload artifact
uses: actions/upload-artifact@v2
with:
name: graphql-api
path: build/gatographql.zipAnd finally, we make use of JasonEtco/upload-to-release upload the .zip file as a release asset, under the release package which triggered the GitHub action. The secret secrets.GITHUB_TOKEN is implicit, GitHub already sets it up for us:
- name: Upload to release
uses: JasonEtco/upload-to-release@master
with:
args: build/gatographql.zip application/zip
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}When tagging the source code with tag v0.1.20, the action is triggered, and we can see in real-time what the process is doing. Once finished, if everything went fine, all the steps executed in the workflow will have a beautiful ✅ mark:

Now, heading to the releases for tag v0.1.20, it displays a link to the newly-create release graphql-api:
Hurray!
]]>Why build your own when one already , and is developed by a gatsby dev?
I reproduce my response here.
I can reply to this question from 3 different angles:
I actually started working on this project much earlier than WPGraphQL. It's just that, when I started with it, I didn't know it would eventually become a GraphQL server for WordPress, or even a GraphQL server!
I started the mental process of thinking about my solution after I published this article on Smashing Magazine, describing an architecture of server-side components to load data:
https://www.smashingmagazine.com/2019/01/introducing-component-based-api/
This article describes the foundation of how my GraphQL server works. It was published in January 2019, before Jason Bahl was even hired by Gatsby.
Around then I learnt about GraphQL, and how it returns exactly the queried data. And with my architecture, I was already solving that problem, and beautifully, since it doesn't employ a graph, so it's super performant.
So then, I had no alternative towards myself than to go ahead, and implement the GraphQL server. It took around 1 year to do. But in the process, I built it to be super super powerful, as I've been trying to show in my series of articles for LogRocket, and sharing in this channel [/r/graphql in Reddit].
And concerning the component-based architecture, when did I start working on it? Its repo, https://github.com/GatoGraphQL/GatoGraphQL, was actually published in September 2016!
So I was working on my GraphQL server way back before I even knew about the existence of GraphQL.
Btw, Jason is doing a great job with WPGraphQL. Launching an alternative to his project is not about posing a challenge. We just happen, by chance, to have implemented 2 different solutions to the same problem...
I don't want to sound arrogant, I truly do not want. But my solution is better. Indeed, I meant it in my original post when I said this is serious GraphQL business. I'm extremely proud of what features it supports and, the best of all, is that the features it can potentially implement are boundless, thanks to the directive pipeline architecture that I described here:
https://blog.logrocket.com/treating-graphql-directives-as-middleware/
WPGraphQL is, on the opposite, quite limited. Its support for directives is quite paltry. This is because it relies on webonyx/graphql-php, which is OK, but nothing great.
I have just published a blog post, comparing my plugin to both WP REST API and WPGraphQL, and explaining what makes my plugin special from a feature-point-of-view. Please read it:
https://leoloso.com/posts/introducing-the-graphql-api-for-wordpress/
I understand the feeling that, if somebody is working on an open source project about the topic I want to implement, then I should contribute there instead of doing my own thing.
But that doesn't apply if your idea to solve the problem is completely different, and can solve the problem better. Imagine if we had declared the problem of search solved by 1994, so that Google would not have been created, and we'd still be searching with Altavista nowadays.
In addition: creating another project brings innovation and improvement all across. Now that my project is out, WPGraphQL has to improve. I'm providing persisted queries. They are not. They will need to implement it, or risk having their users switch to my plugin. Can they implement it? I hope their architecture supports it (I guess it should), but I don't know for sure. What if I had contributed to their project, instead of working on mine? Well, then I couldn't have created 1/10th of what I did using my own architecture.
Have I convinced you with my explanation? 😀
]]>Update 23/01: The GraphQL API for WordPress has its own site now: gatographql.com.
Yesterday I launched the project I've put all my efforts into: the GraphQL API for WordPress, a plugin which enables to retrieve data from a WordPress site using the increasingly popular GraphQL API.

I've been developing this plugin full time for most of the last 12 months. And, taken together with GraphQL by PoP (the CMS-agnostic GraphQL server in PHP, on which it is based), I've spent several years into this project.
So it's a great relief and pleasure to be finally able to release it to the world. In this blog post I explain all about it.
Before anything, let's tackle the elephant in the room. You may be thinking: "Wait a second. Aren't there already API solutions for WordPress?"
Yes, there are. The 2 most popular solutions are WP REST API, which is already part of WordPress core, and WPGraphQL, a plugin which is also based in GraphQL.
"I thought so! But aren't these APIs already good?"
Yes, they are indeed good. The WP REST API is kept always up-to-date with the latest requirements from the WordPress project, most notably concerning Gutenberg. And WPGraphQL, even though it hasn't been published to the WordPress directory yet, has become more stable during the past year, gained an increasing community of users, and is approaching its 1.0 version.
"So then, why do we need yet another solution?"
Possibly, you do not need another solution. If whichever solution you're already using satisfies all your needs, and doesn't give you any trouble at all, then stay there.
But if your solution doesn't fully satisfy your needs, because it's not so fast, secure or friendly to use; it takes plenty of time to code or write documentation for it; it has limitations that hinder your application; or any other reason at all... then hear me out.
These are, I believe, GraphQL API for WordPress's two killer features:
Persisted queries use GraphQL to provide pre-defined enpoints as in REST, obtaining the benefits of both APIs.
With REST, you create multiple endpoints, each returning a pre-defined set of data.
| Advantages |
|---|
| ✅ It's simple |
✅ Accessed via GET or POST |
| ✅ Can be cached on the server or CDN |
| ✅ It's secure: only intended data is exposed |
| Disadvantages |
|---|
| ❌ It's tedious to create all the endpoints |
| ❌ A project may face bottlenecks waiting for endpoints to be ready |
| ❌ Producing documentation is mandatory |
| ❌ It can be slow (mainly for mobile apps), since the application may need several requests to retrieve all the data |
With GraphQL, you provide any query to a single endpoint, which returns exactly the requested data.
| Advantages |
|---|
| ✅ No under/over fetching of data |
| ✅ It can be fast, since all data is retrieved in a single request |
| ✅ It enables rapid iteration of the project |
| ✅ It can be self-documented |
| ✅ It provides an editor for the query (GraphiQL) that simplifies the task |
| Disadvantages |
|---|
❌ Accessed only via POST |
| ❌ It can't be cached on the server or CDN, making it slower and more expensive than it could be |
| ❌ It may require to reinvent the wheel, such as uploading files or caching |
| ❌ Must deal with additional complexities, such as the N+1 problem |
Persisted queries combine these 2 approaches together:
Hence, we obtain multiple endpoints with predefined data, as in REST, but these are created using GraphQL, obtaining the advantages from each:
| Advantages |
|---|
✅ Accessed via GET or POST |
| ✅ Can be cached on the server or CDN |
| ✅ It's secure: only intended data is exposed |
| ✅ No under/over fetching of data |
| ✅ It can be fast, since all data is retrieved in a single request |
| ✅ It enables rapid iteration of the project |
| ✅ It can be self-documented |
| ✅ It provides an editor for the query (GraphiQL) that simplifies the task |
And avoiding their disadvantages:
| Disadvantages |
|---|
POST |
Check out this video on creating a new persisted query:
The GraphQL single endpoint, which can return any piece of data accessible through the schema, could potentially allow malicious actors to retrieve private information. Hence, we must implement security measures to protect the data.
The GraphQL API for WordPress provides several mechanisms to protect the data:
👉 We can decide to only expose data through persisted queries, and completely disable access through the single endpoint (indeed, it is disabled by default).
👉 We can create custom endpoints, each tailored to different users (such as one or another client).
👉 We can set permissions to each field in the schema through Access Control Lists, defining rules such as: Is the user logged-in or not? Does the user have a certain role or capability? Or any custom rule.
👉 We can define the API to be either public or private:
In the public API, the fields in the schema are exposed, and when the permission is not satisfied, the user gets an error message with a description of why the permission was rejected.
In the private API, the schema is customized to every user, containing only the fields available to him or her, and so when attempting to access a forbidden field, the error message says that the field doesn't exist.
Here is an overview of the features shipped with the first version of the plugin.
GraphiQL is a user-friendly client to create GraphQL queries.
The GraphiQL Explorer is an interactive tool attached to GraphiQL, that allows to create the query by point-and-clicking on fields.
These 2 tools are embedded in the plugin, making it very easy to create the queries:

GraphQL Voyager is a tool that enables to explore the GraphQL schema:

As already explained.
A custom endpoint with a specific schema configuration can be created for any target, such as:
The custom endpoint is a Custom Post Type, and its slug becomes the endpoint. An endpoint with title "My endpoint" and slug my-endpoint will:
/graphql/my-endpoint//graphql/my-endpoint/?view=graphiql/graphql/my-endpoint/?view=schema


Every custom endpoint and persisted query can select a schema configuration, containing the sets of Access Control Lists, HTTP Caching rules, and Field Deprecation entries (and other features, provided by extensions) to be applied on the endpoint.

We define permissions to access every field and directive in the schema through Access Control Lists. Shipped in the plugin are the following rules:
New custom rules can be added, such as:

When access to some a field or directive is denied, there are 2 ways for the API to behave:

Because it sends the queries via POST, GraphQL is normally not cacheable on the server-side or intermediate stages between the client and the server, such as a CDN.
However, persisted queries can be accessed via GET, hence we can cache their response.
The max-age value is defined on a field and directive-basis. The response will send a Cache-Control header with the lowest max-age value from all the requested fields and directives, or no-store if either any field or directive has max-age: 0, or if access control must check the user state for any field or directive.

The plugin provides a user interface to deprecate fields, and indicate how they must be replaced.

Persisted queries (and also custom endpoints) can declare a parent persisted query, from which it can inherit its properties: Its schema configuration and its GraphQL query.
Inheritance is useful for creating a hierarchy of API endpoints, such as:
/graphql-query/posts/mobile-app//graphql-query/posts/website/In this hierarchy, we are able to define the query only on the parent posts persisted query, and then each child persisted query, mobile-app and website, will obtain the query from the parent, and define only its schema configuration (as to set the custom access control rules, HTTP caching and deprecated fields) for each application.
Likewise, we can declare the configuration at the parent level, and then all children implement only the GraphQL query.
/graphql-query/mobile-app/posts//graphql-query/mobile-app/users//graphql-query/website/posts//graphql-query/website/users/Children queries can override variables defined in the parent query. For instance, we can generate this structure:
/graphql-query/posts/english//graphql-query/posts/french/The GraphQL query in posts can have variable $lang, which is then set in each of the children queries with the value for the language: "en" and "fr".
The number of levels is unlimited, so we can also create:
/graphql-query/mobile-app/posts/english//graphql-query/mobile-app/posts/french/
When different plugins use the same name for a type or interface, there will be a conflict in the schema. Whenever this happens, enabling schema namespacing will fix the problem, since it prepends all types and interfaces with their namespace.
For instance, if WooCommerce and Easy Digital Downloads both implement a type Product, there there will be a conflict. With namespacing enabled, these types become Automattic_WooCommerce_Product and SandhillsDevelopment_EDD_Product, and the conflict is resolved.

Here a response to some questions I've received:
In theory yes, but since I've just launched the plugin, you'd better test if for some time to make sure there are no issues.
Update 04/02: the plugin is now scoped! So the issue below does not apply anymore 🥳
In addition, please be aware that the GraphQL API has a dependency on a few 3rd-party PHP packages, which must be scoped to avoid potential problems with a different version of the same package being used by another plugin in the site, but the scoping must yet be done.
Hence, test the plugin in your development environment first, and with all other plugins also activated. If you run into any trouble, please create an issue.
Yes, you can, because the GraphQL API for WordPress is extensible, supporting integration with any plugin. But, this integration must still be done!
If there is any plugin you need support for, and you're willing to do the implementation (i.e. creating the corresponding types and resolvers for the fields), please be welcome to create an issue and I will help.
In theory yes, it is doable, but I don't know why you'd want to do that: Jason Bahl, the creator of WPGraphQL, works for Gatsby, so relying on WPGraphQL is clearly the way to go.
Hopefully, everyone! Even though GraphQL involves technical concepts, I've worked hard to make the plugin as easy-to-use as possible.
Following the ethos from WordPress, this plugin attempts to allow anyone, i.e. bloggers, designers, marketers, salesmen, and everyone else, to be able to create an API in a simple way:
Also, because the single endpoint is disabled by default, the risk of unintentionally exposing sensitive data is minimal.
You can, but you will need to rewrite your existing GraphQL queries, because the shape of the schema provided by both plugins is different.
For instance, some differences are:
postTags instead of tagswhere argument for the posts field, handled differently in GraphQL APIUpdate 04/02: the plugin has guides on how to use it, and has been scoped! So the issues below do not apply anymore 🥳
GraphQL API is stable and, I'd dare say, ready for production (that is, after playing with it in development). But some things are not complete yet:
When these two issues are resolved, I may already decide to publish the GraphQL API plugin to the WordPress plugin repository, depending on the feedback I have received by then.
Moving forward, the schema must be completed to cover all WordPress entities, including:
Finally, GraphQL API does not currently support mutations. It must also be implemented.
WordPress is the most popular CMS in the world, because it makes it easy to anyone to create and publish content. It provides a great user experience.
GraphQL is steadily becoming the most popular API solution, because it makes it easy to access the data from a website. It provides a great developer experience.
I believe that the GraphQL API for WordPress can succeed to integrate these 2 together, combining their characteristics: to make it easy to anyone to provide access to their content.
This is, I believe, "democratizing data publishing".
If you like what you've seen, please:
🙏 Try it out
🙏 Star it on GitHub
🙏 Share it with your friends and colleagues
🙏 Talk about it (please do! I have no deep-pockets to promote it, I depend on word of mouth)
And please, give me feedback about your experience, either good or bad. If you enjoyed it and found it useful, please let me know. If you think that something can be improved, let me know. If something didn't work, or something else broke in the site, let me know. Be welcome to create an issue on the repo.

Thanks for reading!
]]>Essentials for building your first Gutenberg block
This article gives a few tips for starting a new Gutenberg project, as I discovered them in my own journey. It's mainly useful for newbies, who either haven't started yet, or have recently begun and are navigating uncharted waters.
As always, I hope you enjoy it!
]]>Here they are, the images of some of my travels, when I was young and energetic (I was even smiling in many of those pics!):






































































































































































































I have the impression than most WordPress developers are in the same situation. So I've been compiling my aha moments, and wrote a couple of articles for the LogRocket blog with my tips.
I just had the first article published:
👉🏻 Setting up your first Gutenberg project
The second part will come next week.
I hope you enjoy it!
]]>I just got the data: the images are resized down (they don't have the original dimensions I uploaded them with), and the data is a dull .json file, which does not reflect any of the personality, feelings or enjoyment that this same piece of data had in the site.
It sucks.
But at least, because the CS reps didn't know how to satisfy my requirements for my own data, they gave me temporary access to the site. So I could log in a final time, and took a few screenshots of my profile in the site.
These are the last glimpses of my CouchSurfing activity, after being a member for 14 years!
My CouchSurfing friends (open big):

My CouchSurfing photos (open big):

My references from surfers (open big):

My references from hosts (open big):

My personal references (open big):

I met many friends. I met my wife. Those were good times.

But that's no more. Couchsurfing (with a lowercase s) is dead. Today I logged-in to the website, and wherever I go, I can only access this screen:

Mind you, if you're logged in, my profile is still available:

But if I click on "Edit my profile", I can't do anything, I can't change my status to "Not hosting". I'm presented the contribution screen.
So I'm being held hostage to access my own data. These guys managing the site are effectively putting a ransom on my own data. To say that this is extremely f*cked up is an understatement.
They say they hear us:
- Aren’t you holding my data hostage?
Nope. We understand some of you feel we are keeping your profiles “hostage” or require that you pay a “ransom”, and apologize for this. This was not the intention we had in trying to rally the community around saving Couchsurfing. We remain compliant with all privacy regulations. As has always been the case, you can ask for a copy of your data and to delete your account by contacting Couchsurfing Support at support@couchsurfing.com or through privacy@couchsurfing.com.
Yeah. Bullshit. Bullshit bullshit bullshit. I can't access my data in the website, I can't edit it, yet my profile is still publicly available.
Aren't these guys liable to be sued through GDPR? I hope they are, and I hope somebody punishes them. CouchSurfing (with uppercase S) was such a beautiful project. Until it was sold out to transform it into a business for personal profit, never mind the website was a community project
(Btw, in their "we hear you" blog post, they mention the word "community" 36 times. Funny. They suddenly remembered about their community... once COVID hit and they couldn't charge for ads any longer; once they could not milk the cow any longer).
I am so angry. These people running Couchsurfing ruined such a beautiful project.
I have requested to delete my user account from the site, including the almost 100 references from both surfing and hosting. 😢
I'd love to show a final screenshot of my reviews, but I can't access them. Or any of the 204 photos I've uploaded to the site, but I can't access any of them. Even though it's all my own data.
So I show my full-length profile instead, with the descriptions of how absurd had the CS site become after it became for-profit.


Why is this happening? For the demonstration for my article, I have needed to print the value of the dynamic variable in the response, as to visualize that it works well. For that, I created a field echoVar, which simply echoes back the value contained in the variable.
Since the type of the values may not be known in advance (it could be a String, Int, any custom scalar, an object, or anything else), the type of echoVar is a generic Mixed type, to which all types can be "identified" with.
The consequence of using Mixed is that there will be a mismatch when loading the query in the GraphiQL client, showing a red line in the argument definitions and an error when hovering over them:
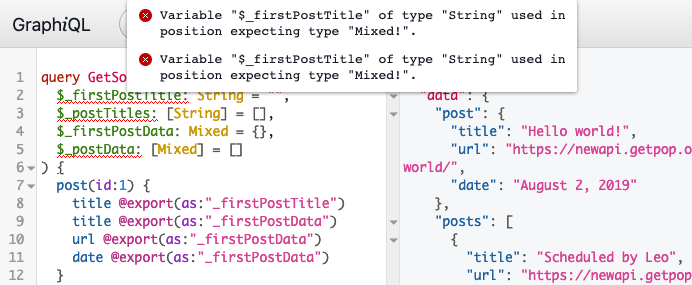
I am not so troubled with this issue, because field echoVar is not actually needed: it was just used to see that @export behaves as expected. However, it is still annoying to see those red lines.
The solution currently supported by GraphQL is extremely verbose and unmaintainable: to create different echoVar functions for each type (echoStringVar, echoIntVar, etc). This issue should be solved in an elegant way, avoiding the verbosity from having to declare a different field per type of response.
The GraphQL spec issue linked to in my article mentions that we could provide @export with an additional argument type, but this is potentially useful only for deducing the type of the object in the GraphQL server. The hack, though, deals with the type of the object in the query, on the client.
So, how to solve this issue? There are 3 possible approaches to it. All 3 are currently unsupported by GraphQL, but this situation could change in the foreseeable future.
Serializable interfaceThe trait in common among all scalar types (Int, Float, Boolean, String and ID, and all custom scalar types) is that they are serializable. Hence, if they implemented a Serializable interface, we could have field echoVar return this interface, and it would be satisfied not matter which actual type it returns.
However, this doesn't work, because the spec says that an interface must include at least one field, but scalar types cannot resolve fields (that's only doable by the Object type). Then, unless the spec is modified, scalar types cannot implement interfaces.
Any scalar typeThe Mixed type I have use to represent any scalar type could be a type all by itself, a kind of wildcard type that says: I represent anything.
This use case is already being dealt with, through this pull request, proposing to add the Any type. However, this pull request is 3 years-old, and doesn't seem to have much activity, so I don't hold my breath about it.
Even though currently only object types can be part of union types, there is a proposal to also support the union of scalar types.
With this solution, field echoVar could be declared to return Int | Float | Boolean | String | ID, and so all of these cases would be covered.
This is the solution that seems most promising of all 3. The issue has had recent activity, is directly related to the GraphQL Input Union proposal, which is currently being worked upon by the GraphQL Working Group, and there is a champion working on it.
]]>🎩 Adding a Custom Welcome Guide to the WordPress Block Editor explains how to leverage the <Guide> component from Gutenberg:

I required a few days of work to pull out this strategy.
💣 Adding Modal Windows in the WordPress Admin Without JavaScript explains how to use the existing modal windows from the plugins page to display arbitrary content, using only PHP and a bit of CSS:

It took me just a few hours to implement this strategy.
In practical terms, both solutions succeeded to open the modal window. The user experience using Gutenberg is very polished, the one without feels hacky. At the same time, the effort of doing something with Gutenberg is much higher than without.
Which solution is better? As always, it depends. If a compelling user experience is mandatory, then Gutenberg is the way to go. But if you just need a simple solution and don't have time or money to spare, a simple hack in the WordPress admin might already do.
]]>In the series on GraphQL I'm writing for LogRocket, I've been arguing that good support for custom directives may be the most important factor for choosing a GraphQL server.
Motivated by this philosophy, I made the engine from GraphQL by PoP (my own implementation of a GraphQL server in PHP, soon to be made available as a WordPress plugin) operate by executing directives. In my architecture, directives are a low-level component, which can manipulate the response in any way the developer needs. Then, directives are full power, and, I'd dare say, there is pretty much nothing that cannot be achieved through some custom directive.
The design for the architecture is first conceived on the concept of middleware:

But then, because in GraphQL directives must be executed in order, this becomes a pipeline:

Ultimately, the pipeline incorporates several elements (system directives @validate and @resolveValueAndMerge, multiple fields as inputs per directive, a single pipeline to handle all directives for all fields, and a few others) to make the most out of GraphQL:

I explain in detail this architecture in my latest installment for the GraphQL series:
Treating GraphQL directives as middleware
I also compare how the directive pipeline fares against field-resolver middleware, as done by graphql-middleware, Sangria, and a few other GraphQL servers.
I hope you enjoy this reading!
👋
]]>For instance, the GraphiQL block is used to create persisted GraphQL queries:
Now, this block is not a content block, but a configuration block: it is used by the Custom Post Type called "GraphQL Persisted Query" to configure the GraphQL server.
I do not want to make this block available when editing a normal post, since it just makes no sense there. Sure, I could just leave it there and never use it, but then the WordPress editor would be polluted with blocks that I do not need, and can't even use, and because they are still loaded the editor takes longer to initialize. So removing it completely whenever not needed seems like a very good idea.
So I wrote a piece for Design Bombs explaining how to do this, using PHP code only:
Registering Gutenberg blocks for a certain custom post type only, using PHP (not JS!)
I consider this solution better than the official JavaScript-based solution, because it's faster, requires less code, and it generally makes more sense (why would you register something in PHP to immediately unregister it in JavaScript? 🤔)
Enjoy! 👋🏻
]]>My upcoming GraphQL API for WordPress plugin offers a solution to this problem: it enables to create "persisted queries", where users can create/publish the query in advance, and remove access to the endpoint. Then, all interaction with the GraphQL server can be done through these admin-generated, pre-approved routes only.
It's a huge win: private data is never exposed, and admins need not worry about attackers sending complex queries to bring the server down.
Check it out in the screencast below, which I recorded using the plugin in my development environment:
In the screencast, I do the following things:
/graphql-query/post-list/, is the persisted query's endpoint to access the data$offset, with an initial value of 0"Accept variables as URL params" is onoffset with value 5 and load the page, obtaining the new responseCoooool, right? 😎
Btw, the GraphQL API for WordPress plugin will be released in barely a few weeks! 😎 😎 😎
]]>Coming from this realization, I wrote piece GraphQL directives are underrated to bring out all the beauty from directives:
As I argue in my article, because most (if not all) new development in GraphQL is initiated through directives, GraphQL servers with good support for custom directives will lead GraphQL into its future. Conversely, APIs implemented on servers with poor support may eventually become stagnant, making them a poor investment for the long-term.
Hence, when searching for a GraphQL server for your new API, priority should be given to their support for custom directives. This is such a strong belief for me, that I coded GraphQL by PoP (my own GraphQL server, implemented in PHP) to have directives as its very architectural foundation. Even calling resolvers is executed through a directive!
(Btw, this will be the topic of the upcoming article on my GraphQL series 😎)
Piece GraphQL directives are underrated is part of a series I'm writing for the LogRocket blog, where I explain my journey on conceptualizing, designing and implementing a GraphQL server, as I have done for GraphQL by PoP.
Enjoy!
]]>I didn't want to mess up this computer installing all the software I need to run my development web server (MAMP, MySQL, configuring hosts and virtual hosts, configuring php.ini, what PHP version to use, what WordPress, and so on), so this was the perfect chance to start using Lando, the Docker-based tool that simplifies setting-up development projects: just configure the requirements in a .lando.yml file in the root folder of the project, run lando start, and voilà, my WordPress site will be up and running.
I hit a problem though: I want to be able to modify the source files, and visualize the changes on the site immediately, without having to sync files across folders, which takes time and makes the process rather cumbersome. In my previous MAMP-based set-up, I achieved this by creating symlinks to my source code in the site folders inside the webserver. Lando, however, runs inside Docker containers, where symlinks are not allowed, because my local files and your local files will be different and Docker attempts to create always the same output, no matter where it runs.
However, this issue can fortunately be solved: Lando maps a few host locations to container locations, including the home folder, which is mapped to /user inside the container. And the contents are kept in sync! Hence, because my source files are hosted under ~/GitHubRepos/, I can reference them within the container as /user/GitHubRepos/.
The final step is to create the symlink within the webserver inside the container. For this, I configured a Lando service to execute the ln command to create the symlink. Since I'm developing a WordPress plugin called "GraphQL API", instead of uploading a .zip file to install it, I created a symlink graphql-api under folder /app/wordpress/wp-content/plugins pointing to the plugin source files, which exist under /user/GitHubRepos/graphql-api, like this:
name: graphql-api
recipe: wordpress
config:
webroot: wordpress
services:
appserver:
run_as_root:
- ln -snf /user/GitHubRepos/graphql-api /app/wordpress/wp-content/plugins/graphql-apiThis works perfectly! Now, when modifying the source code from my repository, I can see the changes take effect immediately on the testing website. 😎
]]>For instance, we can create endpoints:
/graphql/website/graphql/mobile-app/graphql/client-this-one/graphql/client-that-oneEach endpoint is attached its own GraphiQL (under /?view=graphiql) to execute queries, and Voyager (under ?view=schema) to visualize the endpoint's schema (each endpoint can be configured to access only a sub-schema, i.e. certain parts from the grand schema).
Demo in this video (without audio!):
]]>The quality of the video uploaded to YouTube is terrible though 😢, the videos are pretty much static. So in the upcoming days I'll link to each of the demoed videos, which I've uploaded to this channel in Vimeo. It will be 7 posts for 7 demoed functionalities:
→ Custom Endpoints
→ Persisted Queries
→ Access Control Lists
→ Public/Private Schema
→ HTTP Caching
→ Field Deprecation
→ API Hierarchy
Oh, btw, the plugin will ship with even more features! 🚀
The announcement has been made! The countdown to releasing the plugin has begun 😎
]]>My plugin Block Metadata makes it even easier, offering a process to easily expose our own metadata from our own blocks. The plugin's final goal is to make the content in our WordPress websites become the single source of truth of content for all our digital applications, following the COPE (Create Once, Publish Everywhere) strategy.
In my latest article for Design Bombs I describe how to export our site's data to power a mobile app. Enjoy!
]]>Today I have fixed this issue. Now, the specific version for a field/directive can be provided to the endpoint through URL params, so it can be incorporated when generating the schema artifact. This way, clients and tooling have complete visibility of all possible versions of the schema, allowing to:
Two new URL params to pass to the endpoint were created:
fieldVersionConstraints[]directiveVersionConstraints[]These params are arrays, so they can be defined multiple times in the URL as to version more than 1 field or directive. Directives are referenced directly by their name (without the @), like this:
?directiveVersionConstraints[makeTitle]=^0.1&directiveVersionConstraints[upperCase]=~0.2Fields are referenced as a combination of their type and their name, separated with a dot, like this:
?fieldVersionConstraints[Post.title]=0.3.1&fieldVersionConstraints[User.name]=0.2|0.3The type name can be namespaced or not, it will work in either case, with automatic namespacing enabled or not.
Now, the algorithm follows this order to obtain the versioning of a field:
fieldVersionConstraints[] on the namespaced typefieldVersionConstraints[] on the non-namespaced typeversionConstraintFor directives it is similar, but in only 3 steps since they are not namespaced:
directiveVersionConstraints[] on the directiveversionConstraintIf no versioning is found on any of these steps, then the field or directive is not versioned.
Let's check out some examples. In the GraphiQL clients below, the URL parameters fieldVersionConstraints[] and directiveVersionConstraints[] were added to the endpoint /api/graphql/ (check it out in the Network tab in Firefox/Chrome DevTools).
In this query, field userServiceURLs is queried with version 0.1.0 set by field argument, and with version 0.2.0 by default, as set through URL param fieldVersionConstraints[Root.userServiceURLs]=^0.2:
To double check that the default field has version 0.2.0, we can click on the documentation explorer, browse to Root.userServiceURLs, and read the version added to its description:
Services used in the application: GitHub data for a specific repository (Version: 0.2.0)
Or we can also visualize it with GraphQL Voyager, which displays the schema for the specified exact combination of field and directive versions:

It works the same way for directives. In this query, directive makeTitle is queried with version 0.2.0 set by directive argument, and with version 0.1.0 by default, as set through URL param directiveVersionConstraints[makeTitle]=^0.1:
Of course they can be combined. In this query we are independently setting the version for fields userServiceURLs and userServiceData, and directive makeTitle:
I have added tons of new features to GraphQL by PoP lately. It is now finally time to work on providing documentation (so I am not the only one who can get to use it!). For that, the following weeks I will be completing the documentation on the newly-launched GraphQL by PoP site.
GraphQL by PoP is currently available for WordPress, to be installed via Composer. In the upcoming weeks/months, I will attempt to release the WordPress plugin, which will be very easy to install, and will contain several wonderful features:
Most of the features are ready, and I can already say: they are so awesome! Check out this screenshot:
")
Exciting times are coming!
If you install GraphQL by PoP and run into any trouble, let me know and I'll help: DM me on Twitter, chat on the GraphQL Slack channel, or email.
Arrivederci! 👋
]]>This site is powered by VuePress, the Vue-centric static site generator for documentation. And it's soooo beautiful! I'm extremely pleased with the results so far. 😍
I have already completed the homepage and installation page. I'll keep working on the rest of the documentation during the upcoming few weeks (it will take quite some time, since I have a lot to catch-up).
GraphQL by PoP is finally getting into "usable" mode. So now more than ever, check it out!
@removeIfNull (as to be able to distinguish between null and omission values in the response), and today I created directives @cache and traceExecutionTime. Let's check them out.
The @cache directive enables to cache the result of a heavy-to-compute operation. The first time the field is resolved, the @cache directive will save the value in disk or memory (Redis, Memcached), either with an expiry date or not, and from then on whenever querying this field the cached value will be retrieved and the operation will not be performed.
Please notice: the
@cachedirective is different than the@cacheControldirective, which sends theCache-Controlheader with amax-ageto have the browser/CDN/webserver cache the response through HTTP caching.With these two directives, the caching solution in GraphQL by PoP is now very robust: HTTP caching + Field-computation caching!
To find out more: the
@cacheControldirective is demonstrated in this blog post (it shows examples using the PoP Query Language, but it works the same way for GraphQL when passing the query through GET, or when using persisted queries).
For instance, this query executes the @translate directive, which does a single connection to the Google Translate API and performs the translation of the posts' titles:
Assuming this is an expensive call, we would like to cache the field's value after the first response. This query achieves that through the @cache directive, passing a time expiration of 10 seconds (not passing this value, the cache does not expire). To visualize it, run this query and then, within 10 seconds, run it again:
Please notice that directives in GraphQL are applied in order, so the following queries are different:
title @translate @cachetitle @cache @translateIn the 1st case, it executes
@translateand then@cache, so the translation is being cached; in the 2 case, it executes@cacheand then@translate, so the caching only stores the value of thetitlefield and not its translation.
How do we know that the 2nd time the response came from the cache? If you notice, the endpoint is passed a parameter actions[]=show-logs which prints logs under the extensions top-level entry. The first time we execute the query, we obtain this response:

The 2nd time, executing the same query within 10 seconds, we obtain this response, in which a log informs that the value is coming from the cache:

Please notice how the log indicates which are the items that have been cached: in this case, the same 3 items being filtered. If we increase the limit to 6, and run again within 10 seconds, the already-cached 3 items will be retrieved from the cache, and the other 3, which have not been cached yet, will be retrieved fresh through Google Translate:

If we run it again, now all 6 items will be cached:

Needless to say, the query retrieving cached fields feels faster. But how much faster? Can we quantify it?
Yes, we can quantify it, because I also implemented the perfect companion: the @traceExecutionTime directive tracks how much time it takes to resolve the field (including all the involved directives), and adds the result to the log. Let's check it out using the same earlier example.
Let's run this query with @traceExecutionTime first, and within 10 seconds again:
For the first execution, resolving the field containing the @translate directive took 80.111 milliseconds to execute (from connecting to the Google Translate API):

For the second execution, the results from translating the titles were all cached, so the connection to Google Translate was avoided and the field was resolved in less than 1 millisecond:

That is 80 times faster! How cool is that!? 👏👏👏
Yes, you can install it following these instructions, but the documentation right now is all over the place and not easy to follow (there is a bit in this blog, some bits in this GitHub repo and a few others, some other stuff in a few Smashing Magazine and LogRocket blog articles). It's certainly not ideal.
But don't despair! I'm working on a new documentation site, and then it will be perfect! It should be ready in a few weeks time... I will post updates in this blog and on my Twitter account.
Hasta la vista 👋
]]>Being able to difference between null and omissions in the query response is a great example of a feature that can be tackled through directives. When retrieving data through GraphQL, we may sometimes want to remove a field from the response when its value is null. However, GraphQL currently does not support this feature.
So I decided to implement it as a directive: @removeIfNull. Its code barely occupies a few lines, with this logic:
null, unset it from the objectTadaaa, that's it! Check it out here:
]]>Versioning the schema this way solves a basic problem produced by the evolution strategy adopted by GraphQL: when deprecating a field, as to replace it with a newer implementation, the new field will need to have a new field name. Then, if the deprecated field cannot be removed (eg: because some clients are still accessing it, from queries that were never revised), then these fields tend to accumulate, making the schema have different fields for a same functionality, most of them already outdated, and the new, latest implementation of the field not able to have the original field name, indeed polluting the schema and making it not as lean as it should be.
Let's see it in action. In this query, field userServiceURLs has 2 versions, 0.1.0 and 0.2.0, and we can choose one or the other through field argument versionConstraint:
Please notice that the name of the argument is not version by versionConstraint: we can pass rules to select the version, following the semantic versioning rules used by Composer:
It works for directives too:
What happens if we do not pass the versionConstraint? This depends on the implementation of the API, which can choose what strategy to follow:
Use the old version by default, until a certain date in which the new version becomes the default:
Keep using the old version until a certain date, in which the new version will become the default one to use; while in this transition period, ask the developers to explicitly add a version constraint to the old version before that date, through a new warning entry in the query:
Use the latest version, and encourage the users to explicitly state which version to use:
Use the latest version of the field whenever the versionConstraint is not set, and encourage the users to explicitly define which version must be used, showing the list of all available versions for that field through a new warning entry:
Adding the versionConstraint parameter in the GraphQL endpoint itself (set in the GraphiQL client below as /api/endpoint/?versionConstraint=^0.1) will implicitly define that version constraint in all fields:
Any field can still override this default value with its own versionConstraint:
We can also add the versionConstraint parameter in the GraphQL Voyager to visualize the schema for a specific version. For instance, in the default schema:

...field userServiceURLs has the following signature, which corresponds to version 0.1.0:

However, when adding ?versionConstraint=^0.2 to the URL (which in turn sets this parameter on the endpoint), we can visualize the schema for that version constraint. Then, field userServiceURLs has this different signature, corresponding to version 0.2.0:

Please also notice that I have added the field's version as part of the field's description; that is because, currently, GraphQL doesn't feature a version attribute queryable through introspection.
]]>This strategy works great, however it has a problem: these dependencies, which are defined in composer.json, cannot be commited into the repository, since they are specific to the computer used for development. Until today, I had to remove these dependencies each time I made a change to this file, and then added them again.
No more! I just discovered a tool that manages to solve this problem: composer-merge-plugin. This tool enables to merge several composer.json files, so now I can define another file, called composer.local.json, containing the dependencies pointing to my local folder:
{
"autoload": {
"psr-4": {
"Leoloso\\ExamplesForPoP\\": "../../../Libraries/leoloso/examples-for-pop/src"
}
}
}This file was added to .gitignore, so it's just mine, not added to the repo.
Finally, in file composer.json we can merge the configuration with file composer.local.json:
{
"require": {
"leoloso/examples-for-wp": "dev-master",
"wikimedia/composer-merge-plugin": "^1.4"
},
"extra": {
"merge-plugin": {
"include": [
"composer.local.json"
],
"recurse": true,
"replace": false,
"ignore-duplicates": false,
"merge-dev": true,
"merge-extra": false,
"merge-extra-deep": false,
"merge-scripts": false
}
}
}Now, if the file composer.local.json is present, it will override the src for dependency "leoloso/examples-for-wp": instead of using the files from under vendor/, it will use the ones in my local repo, in my folder Libraries/leoloso/examples-for-pop/src, which I am currently developing, saving the time from having to execute composer update constantly.
Handy!
]]>A mandatory directive can, itself, have its own set of mandatory directives which are also added to the directive chain up.
This feature is extremely powerful, since it allows to easily configure what directives are added to the query under what circumstances, as to implement any IFTTT strategy. It supports adding the following capabilities to our GraphQL API:
Define the cache control max-age a field by field basis
Attach a @CacheControl directive to all fields, customizing the value of the maxAge parameter: 1 year for the Post's field url, and 1 hour for field title.
Set-up access control
Attach a @validateDoesLoggedInUserHaveAnyRole directive to field email from the User type, so only the admins can query the user email.
Synchronize access-control with cache-control
By chaining up directives, we can make sure that, whenever validating if the user can access a field/directive, the response will not be cached. For instance:
@validateIsUserLoggedIn to field me@CacheControl with maxAge argument value of 0 to directive @validateIsUserLoggedIn.Beef up security
Attach a @validateIsUserLoggedIn directive to directive @translate, to avoid malicious actors executing queries against the GraphQL service that can bring the server down and spike its bills (in this case, @translate is based on Google Translate and it pays a fee to use this service)
In this schema, the User type has fields roles and capabilities, which I consider to be sensitive information, so it should not be accessible by the random user.
Then, I created package Access Control List for User Roles to attach directive @validateDoesLoggedInUserHaveAnyRole to these two fields, configured to validate that only a user with a given role can access them (code here):
if ($roles = Environment::anyRoleLoggedInUserMustHaveToAccessRolesFields()) {
ContainerBuilderUtils::injectValuesIntoService(
'access_control_manager',
'addEntriesForFields',
UserRolesAccessControlGroups::ROLES,
[
[RootTypeResolver::class, 'roles', $roles],
[RootTypeResolver::class, 'capabilities', $roles],
[UserTypeResolver::class, 'roles', $roles],
[UserTypeResolver::class, 'capabilities', $roles],
]
);
}When executing the query, dear reader, you won't be allowed to access those fields, since you are not logged in (which is validated before checking if the user has the required role):
]]>Code-first vs. schema-first development in GraphQL
This article describes the 2 approaches to implementing a GraphQL server:
In the article I compare both approaches, listing down the advantages and drawbacks of each, recommending when to use one or the other, and finally expressing why I prefer the code-first approach since it enables to support a myriad of features in GraphQL by PoP which would not be feasible otherwise.
This is an ongoing series, and coming soon will be more article on the different strategies employed to tackle all different concerns: decentralization, federation, security, and others.
Enjoy!
]]>“Don't think in graphs, think in components: Simplifying the GraphQL data model”
This article describes how the GraphQL server can use components as the data structure to represent the information (instead of using either graphs or trees), which has these benefits:
For instance, let's say we have the following GraphQL query:
{
featuredDirector {
name
country
avatar
films {
title
thumbnail
actors {
name
avatar
}
}
}
}Using a graph, the data structure we must handle to solve the query is the following one:
My strategy is, instead, to place the different components in a queue, one component per type and ordered from top to bottom in the graph (i.e. traversing from root to leaves), and then these can be processed in iterations:
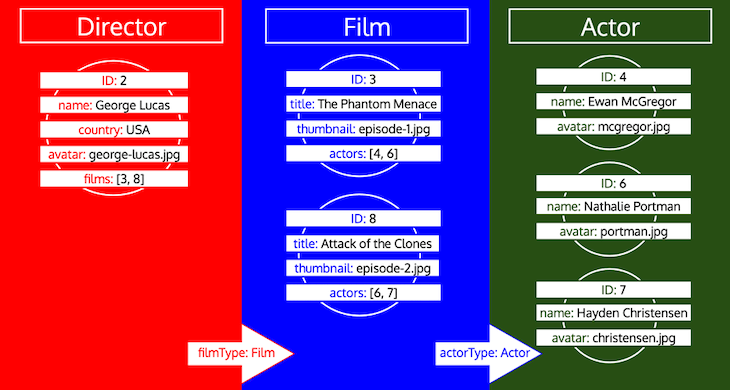
Using a queue, the number of queries executed against the database to fetch data grows linearly on the number of types involved in the query. In other words, its big O notation is O(n), where n is the number of types involved in the query. This performance is much better than using graphs or trees, which, if not handled properly, could have an exponential or logarithmic time complexity (meaning that a graph a few levels deep may become extremely slow to resolve).
Hence, this approach is simple and fast. I explain fully how and why this strategy works in my article for LogRocket.
This is an ongoing series, and coming soon will be more article on the different strategies employed to tackle all different concerns: decentralization, federation, security, and others.
Enjoy!
]]>Bootstrapping WordPress projects with Composer and WP-CLI
Following the method I described in this guide, it literally takes seconds to launch a new WordPress site, making it ideal when we need to launch multiple instances of a site (DEV, STAGING, PROD) or when we produce WordPress sites for clients.
After we have created the database, and set-up the environment variables with its information, we just need to run:
$ composer create-project leoloso/wp-install new_wp_site...and this script will install the new WordPress site:
The source code for this project is in this repo. Enjoy!
]]>The first article is out now: Designing a GraphQL server for optimal performance. Enjoy!
]]>The first one would enable to have fields compose other fields, like this:
query {
posts {
date: if(
condition: equals(
value1: lang,
value2: "ZH"
),
then: "Y-m-d",
else: if(
condition: equals(
value1: year(
date: date
),
value2: currentYear
),
then: "d/M",
else: "d/M/Y"
)
)
}
}The second one would allow directives compose other directives using <> as syntax instead of @, like this:
query {
posts:posts(limit:10) {
tagNames
translatedTagNames:tagNames<
forEach<
translate(from:"en", to:"es")
>
>
}
}I have already added these features on GraphQL by PoP (for instance: query solving the 1st issue, query solving the 2nd issue), and they have proved so powerful that I have no doubt that the GraphQL community could also benefit from them. They just make so much sense!
I wonder if they will be accepted? I certainly hope so! 😆
]]>I have just made the types and interfaces in GraphQL by PoP be automatically namespaced!
This is how the normal schema looks like in the GraphQL Voyager:
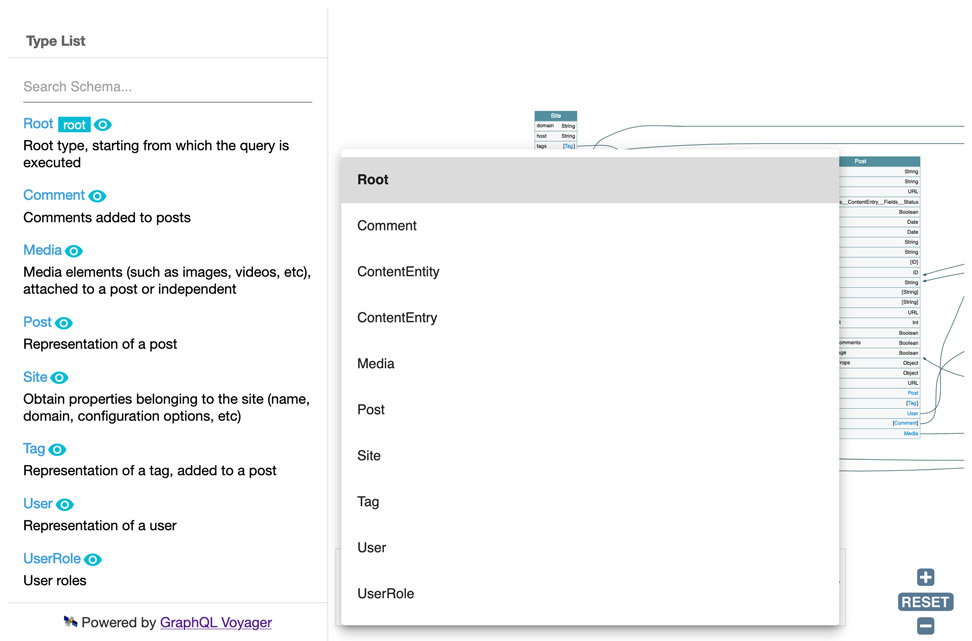
This is how it looks in its namespaced version:
In the namespaced schema, all types are automatically prepended using the PHP package's owner and name (in this case it is PoP_ComponentModel_, where PoP is the package owner, and ComponentModel is the package name).
Namespaces help manage the complexity of the schema. This is particularly useful when embedding components from a 3rd party, where we can't control how the types have been named. For instance, different plugins in WordPress may implement a Product custom post type (such as WooCommerce or Easy Digital Downloads); if they wish to create a GraphQL type for it, they can't just name it Product or it may clash with another plugin. Hence, they would have to manually prepend their type names with the company name (such as doing WooCommerce_Product), which is not the most beautiful solution.
Now, GraphQL by PoP enables to define an environment variable, and it will automatically prepend all types from a package with the PHP namespace used for that package (following the PSR-4 convention, PHP namespaces have the form of ownerName\projectName, such as "PoP\ComponentModel").
There are many more use cases where namespaces can be pretty useful, listed down in this GitHub issue.
If you want to play with the namespaced schema, you can do it in the GraphiQL clients below.
This is the GraphiQL client in normal mode:
An this is the GraphiQL client in namespaced mode (which is enabled by adding URL param use_namespace=1):
I'll end my blog post as usual: if you are using WordPress and you need a kick-ass API, then give GraphQL by PoP a try, what are you waiting for!?
Oh, you're waiting for the plugin, you say?
Well, good news then... it is coming sooooon...

This is going to be gooooood stuff, I promise! 🤪
]]>Of course I had to deploy it on my own server! So here is the interactive schema for my GraphQL API demo site. Doesn't it look gorgeous?
Since my GraphQL server is integrated to WordPress, it is very easy to visualize all the relationships from the WordPress database.
(I'm still completing the different types, properties and relationships in my schema, so this visualization still does not mirror the whole WordPress data model... this will hopefully be finished in the upcoming weeks.)
This is how the interactive GraphQL looks like (even though a bit compressed here!):
This is such a powerful and beautiful visualization of the data graph. Kudos to the contributors from this great project!
]]>Here they are:
]]>Because now it's officially GraphQL, I will simply call this project GraphQL by PoP 😁.
The API comes in 2 modes:
Note: The demo website runs on WordPress, has the GraphQL endpoint here, and its GraphiQL client is here.
Since supporting introspection field "__schema", we can now use GraphiQL's Doc Explorer to read the schema documentation:
I must still add support for mutations. I have already started work on it, and depending on my time availability, I may be able to finish it in a couple of months.
If your project uses WordPress, you can already use it (the API is CMS-agnostic, so it can also work with Symfony/Laravel/Joomla/Drupal, however adapters for them have not been implemented yet).
So give GraphQL by PoP a try, you won't regret it! And let me know how it goes 🙏
]]>The missing part, which I finished adding today, was the GraphQL syntax parser. Until today, the PoP API relied on its own syntax (which is needed to support the engine's broader set of features compared to a standard GraphQL server, such as composable fields, composable directives, and others). However, I had the realization that this custom syntax is a superset of GraphQL's syntax and, as such, it would not be a problem to support it. After exploring all the existing GraphQL server implementations in PHP, I took the one implemented by Youshido and used their parser, and it works like magic!
Let's play with this brand-new implementation of GraphQL, to make sure it works as expected. For this, I have set-up this WordPress site, and installed in it the GraphQL API for PoP, available under this endpoint.
The GraphiQL clients below contain queries to demonstrate the GraphQL features. Click the round button (with alt text "Execute query (Ctrl-Enter)") to execute the query and see the results, and you can also edit the query and the variables and run it again.
Alternatively, you can access the website's own GraphiQL client here.
Note: there are no docs and no information hinting yet, because I still need to support field
"__schema"(see section below).
Fields (Open in website's GraphiQL client)
Field arguments (Open in website's GraphiQL client)
Aliases (Open in website's GraphiQL client)
Fragments (Open in website's GraphiQL client)
Operation name (Open in website's GraphiQL client)
Variables (Open in website's GraphiQL client)
Variables inside fragments (Open in website's GraphiQL client)
Default variables (Open in website's GraphiQL client)
Directives (Open in website's GraphiQL client)
Fragments with directives (Open in website's GraphiQL client)
Inline fragments (Open in website's GraphiQL client)
100% compliance of the GraphQL spec is almost there. The remaining items to implement are:
"__schema" fieldI'm already working on the first item, I expect it to be finished in a few days. Concerning the second item, I have already started work on it, depending on my time availability I may be able to finish it in a couple of months.
Bonus feature: From a unique source code, the API also supports REST! Check out these example links:
Currently, WordPress users have two API alternatives:
Now, I want to add a third alternative:
Please check it out, it will make your life easier. I promise. And let me know how it goes.
]]>Good news is that, as with many other activities, the more you write, the easier it becomes. Hence, there is no better activity to become a proficient writer than to write. For which, the best recommendation I can give you is to have your own blog and post constantly.
When I say blog, I mean your own blog site, under your own domain, and with a style that suits your personality. Yes, you can use Facebook, but Arrggh! It's so ugly and characterless! (As a side note, I don't use Facebook, and if somebody asks me to read their content on Facebook, they have already lost face with me.) Yes, you can use Twitter, but hopefully your write-up can be extensive and will need more than 280 characters. (And they are not mutually exclusive: the best deal is to publish your content on your own blog, and promote it through Twitter.) Yes, you can use Medium, but why would you freely give your content away to some platform to profit from it and be bound by their rules, when you can set-up your own WordPress site in minutes and own your own data?
Nothing really beats your own blog. There you set-up your own rules. You can write about anything you want, and with no constraints as how short or long it must be. You can publish an article today, update it in 1 week, pin it to the top again in 1 year. And if the article starts becoming serious enough, then you can decide to upgrade it even more and submit it to a respectable online magazine. If you need more reasons to write on your own site, here are many writers expressing why they do it.
As much as you need to write, you also need to read. In the realms of literature, good writers are known to be avid readers; that's how they incorporate the tools that makes their prose become great, even if it happens subliminally. Writing about tech is no different: reading articles from other writers will greatly help you gain better ways of expressing yourself.
Once again, when I say read, I don't mean to read tweets (even though there is certainly an art to tweeting, and writing a good tweet can be more difficult than a good long post), but to read articles on tech sites and visiting other writers' personal blogs. For instance, I read Smashing Magazine daily, and some of my favourite blogs are those by Jeremy Keith (from whom I learn how to build the foundations of a website), Tim Kadlec (from whom I learn about performance) and Jake Archibald (from whom I learn about API design and service workers, and he makes me laugh). And I follow other writers on and off as my interest on their topics (CSS, typography, accessibility, serverless, and others) increases and wanes.
The wonderful thing about the internet is that the person who created the technology that you are describing, or wrote a tutorial on how to use it, or has spent countless hours contributing to the open source project, is just one email or direct message away from you. So don't be shy! If you need help, ask for it, and you may receive the assistance that you need. Of course that depends on each expert; some of them are humble and welcoming, some others make it very difficult to be contacted and don't reply, but there is no harm in trying.
In my case, I got stuck when writing my Smashing guide on using Composer with WordPress, and my article suffered as a consequence. So I contacted Andrey “Rarst” Savchenko, who authored the documentation I was following, and asked him to review the article. Within two hours he told me what I had done wrong, and I could fix my article satisfactorily.
Some of the best ideas to write about will not come to your head while you're stuck looking at your phone, browsing that endless Twitter feed. On the opposite, they will come when you completely disconnect, when your brain is not engaged on any activity. By disconnecting you can be yourself, and you can let your creativity flourish. If you are constantly consuming information on social media, your thoughts are being constantly shaped by what you are reading, and you become an extension of the system. It is only by truly spending time on your own and away from the screen, that your thoughts can become free and unrestrained, not being muddled with what everyone else is thinking or saying.
Hence, as superfluous as it may appear, taking breaks is an incredibly important task to get right. It is indeed so important, that you should slot time in your calendar to disconnect. In my case, some of my brightest insights came to me while hiking in the park (which I do without carrying my mobile phone on me) and swimming, and I try as much as possible to do at least one of these two activities on a daily basis.
]]>Below, I will share how I manage to reply that question for myself, for each article I've written so far (mainly on Smashing Magazine and here, on my own blog), and for all the ones I hope to write in the future.
In first instance, there are no topics out of bounds. It could be something very simple, like a trick you discovered today by accident and that many other people could benefit from. It could also be something related to your field of expertise. Do you want to talk about the latest trends in Artificial Intelligence? Go for it! Have you installed a new Content Management System and want to describe how smooth the experience was? Sure, why not! Have you prolonged your users' browsing time on your site and want to share how you achieved it? Absolutely! Do you want to explain how you created that still-life using only HTML and CSS? Please do it!
As a starter to decide the topic of your article, you can simply find out what you are good at and focus on that. You may think that you are not entitled to write since you're not the best concerning your area of work. And you know what? You are right. But only in part: Yes, you are not the best, since there is always somebody out there with more knowledge than any of us about any topic (allegedly not even Charlie Chaplin could win a competition on imitating Chaplin).
But that doesn't mean you can't write about your topic! You don't need to be the best... You only need to be good enough, and to have the conviction to do it... (eventually you will feel very confident, but that comes with time and practice). And if you don't feel confident enough, remember that even those people we consider experts sometimes do not feel confident enough themselves!
In my case, I have a backlog of ideas which I keep revisiting and updating, and which acts as the source for my articles. This is how it works: I just start with an idea. I write my initial idea down on a simple .txt file, and let it grow over the days and weeks, adding new ideas as they come to my head, upgrading previous ones, and removing those ones that make no sense anymore. After some time, as the ideas accumulate and take a certain shape, the foundation for the article will be established. The rest is to write it.
As Stephen King explained in his book "On writing", he doesn't plan a story in advance, but lets the own characters within the story develop it. I feel it is the same for me: Having established a good foundation through the backlog of ideas, I find it very manageable to write the article, since all uncertainties of the "what" are dealt with (and also the how: just arranging the sections into a proper order, adding content, and giving it coherence).
Once the topic of the article is chosen, we gotta write it! That's the topic for my next blog post.
Until then!
👋
]]>OMG, look at that picture of mine in their site, I look huge!


You will need a proper command of English, without making grammar errors or typing typos. However, publishing in an online magazine or in your own blog is not akin to taking part in a literary competition, so you don't need to be a Charles Dickens or an Oscar Wilde to cut the mustard. For instance, my mother tongue is not English, however I reckon that my articles are written well-enough to be understood. Also, your way of expressing your ideas in writing needs to be coherent, or otherwise readers may not understand what you intend to convey. So before you submit your proposal, you can ask your colleagues or friends to read a sample of your write-up, ask them what they understand from it, and make sure it's the same as was intended.
Writing is a commitment which requires time and energy. In my case, considering all the time spent all throughout the process (jotting down ideas, writing the article, editing it, incorporating feedback, reviewing it many times, and several others), an article for Smashing Magazine takes around 5 full days of work on average, plus the research time, which could take a few days or, in some cases, even weeks.
So being able to manage your time adequately is a must. As a starter, choose a topic that you can persevere writing about, and which will not get out of hand (for instance, had I chosen to add 1 or 2 extra CMSs to my Smashing article comparing WordPress and October CMS, I would've been unable to cope with it). Additionally, you can consider asking your employer for time off work, and devote that time to write your article. After all, mentioning the name of your company in your article (even if only on the author's description) may already make it worth it.
Different factors are in play for deciding if an article is valuable, such as its amount of creativity, the depth of its research, the degree of technical knowledge involved, the newsworthiness of the concerned topic and the size and composition of the target group who will benefit from reading it, among many others. From the universe of all possible factors, I believe that the most important one is the clarity of explanation.
I will elaborate by showcasing a piece submitted to Smashing Magazine: article Understanding And Using REST APIs, which focuses on the REST API. Taking into account that this article was published in January 2018, that the concept of the REST API was invented already in 2000 and popularized in 2006 (when Twitter made available its REST API), and that REST had its apogee and is nowadays possibly in decline (with GraphQL claiming its place), I would have expected that, by year 2018, everything would be said about it. Yet, this piece has, to date, received 122 comments, making it an extremely popular article. How did this happen?
Reading the article, it is evident that its popularity arises from its clarity of explanation of the concepts involved. The author does not assume at any moment that the reader knows what a REST API is or how to use it (or any amount of technical knowledge), but explains these in very detailed steps and providing plenty of examples. Through the comments, many readers expressed their satisfaction about the article's comprehensibility:
Thank you, that was the most simple guide I ever came across. I bet will help loads of beginners.
Very nice, simple and comprehensive article on REST. thumbs up
Thanks very much for this! Its so concise extremely helpful for those of us just starting. Keep doing what you do!
Excellent article, Zell. Thanks for the efforts to make one simple to read and comprehensive.
Awesome! Great article and easy to understand. Thanks Zell!
This article evidences that, even if a technology is old, new content can still be created about it if it satisfies the needs of the people who must use the technology. And the most important need is: people must understand it. Hence, the more concise and comprehensible the write-up, the more valuable it becomes.
]]>I can now claim my attempt was a success: The implementation satisfies the GraphQL spec (except for the syntax... more on this below), adding native support for HTTP caching was straightforward, and I could even add new features that the typical GraphQL implementation out there does not support.
So, I'd say this is a good time to introduce this API to the world, and hope that the world will notice it: Please be introduced to the brand-new PoP API, an iteration and improvement over GraphQL.
Below is the set of its unique, distinctive features (displayed through slides here).
Structure of the request:
/?query=query&variable=value&fragment=fragmentQueryStructure of the query:
/?query=field(args)@alias<directive(args)>This syntax:
This syntax can be expressed in multiple lines:
/?
query=
field(
args
)@alias<
directive(
args
)
> Advantages:
{ and } like GraphQL)Example:
/?
query=
posts(
limit: 5
)@posts.
id|
date(format: d/m/Y)|
title<
skip(if: false)
>The syntax has the following elements:
(key:value) : Arguments[key:value] or [value] : Array$ : Variable@ : Alias. : Advance relationship| : Fetch multiple fields<...> : Directive-- : FragmentExample:
/?
query=
posts(
ids: [1, 1499, 1178],
order: $order
)@posts.
id|
date(format: d/m/Y)|
title<
skip(if: false)
>|
--props&
order=title|ASC&
props=
url|
author.
name|
urlBecause it is generated from code, different schemas can be created for different use cases, from a single source of truth. And the schema is natively decentralized or federated, enabling different teams to operate on their own source code.
To visualize it, in addition to the standard introspection field __schema, we can query field fullSchema:
/?query=fullSchemaField and directive argument names can be deduced from the schema.
This query...
// Query 1
/?
postId=1&
query=
post($postId).
date(d/m/Y)|
title<
skip(false)
>...is equivalent to this query:
// Query 2
/?
postId=1&
query=
post(id:$postId).
date(format:d/m/Y)|
title<
skip(if:false)
>All operators and functions provided by the language (PHP) can be made available as standard fields, and any custom “helper” functionality can be easily implemented too:
1. /?query=not(true)
2. /?query=or([1,0])
3. /?query=and([1,0])
4. /?query=if(true, Show this text, Hide this text)
5. /?query=equals(first text, second text)
6. /?query=isNull(),isNull(something)
7. /?query=sprintf(%s API is %s, [PoP, cool])
8. /?query=contextThe value from a field can be the input to another field, and there is no limit how many levels deep it can be.
In the example below, field post is injected, in its field argument id, the value from field arrayItem applied to field posts:
/?query=
post(
id: arrayItem(
posts(
limit: 1,
order: date|DESC
),
0)
)@latestPost.
id|
title|
dateTo tell if a field argument must be considered a field or a string, if it contains () it is a field, otherwise it is a string (eg: posts() is a field, and posts is a string)
Operators and helpers are standard fields, so they can be employed for composable fields. This makes available composable elements to the query, which removes the need to implement custom code in the resolvers, or to fetch raw data that is then processed in the application in the client-side. Instead, logic can be provided in the query itself.
/?
format=Y-m-d&
query=
posts.
if (
hasComments(),
sprintf(
"This post has %s comment(s) and title '%s'", [
commentsCount(),
title()
]
),
sprintf(
"This post was created on %s and has no comments", [
date(format: if(not(empty($format)), $format, d/m/Y))
]
)
)@postDescThis solves an issue with GraphQL: That we may need to define a field argument with arbitrary values in order to provide variations of the field's response (which is akin to REST's way of creating multiple endpoints to satisfy different needs, such as /posts-1st-format/ and /posts-2nd-format/).
Through composable fields, the directive can be evaluated against the object, granting it a dynamic behavior.
The example below implements the standard GraphQL skip directive, however it is able to decide if to skip the field or not based on a condition from the object itself:
/?query=
posts.
title|
featuredimage<
skip(if:isNull(featuredimage()))
>.
srcExactly the same result above (<skip(if(isNull(...)))>) can be accomplished using the ? operator: Adding it after a field, it skips the output of its value if it is null.
/?query=
posts.
title|
featuredimage?.
srcDirectives can be nested, unlimited levels deep, enabling to create complex logic such as iterating over array elements and applying a function on them, changing the context under which a directive must execute, and others.
In the example below, directive <forEach> iterates all the elements from an array, and passes each of them to directive <applyFunction> which executes field arrayJoin on them:
/?query=
echo([
[banana, apple],
[strawberry, grape, melon]
])@fruitJoin<
forEach<
applyFunction(
function: arrayJoin,
addArguments: [
array: %value%,
separator: "---"
]
)
>
>An expression, defined through symbols %...%, is a variable used by directives to pass values to each other. An expression can be pre-defined by the directive or created on-the-fly in the query itself.
In the example below, an array contains strings to translate and the language to translate the string to. The array element is passed from directive <forEach> to directive <advancePointerInArray> through pre-defined expression %value%, and the language code is passed from directive <advancePointerInArray> to directive <translate> through variable %toLang%, which is defined only in the query:
/?query=
echo([
[
text: Hello my friends,
translateTo: fr
],
[
text: How do you like this software so far?,
translateTo: es
],
])@translated<
forEach<
advancePointerInArray(
path: text,
appendExpressions: [
toLang:extract(%value%,translateTo)
]
)<
translate(
from: en,
to: %toLang%,
oneLanguagePerField: true,
override: true
)
>
>
>Cache the response from the query using standard HTTP caching.
The response will contain Cache-Control header with the max-age value set at the time (in seconds) to cache the request, or no-store if the request must not be cached. Each field in the schema can configure its own max-age value, and the response's max-age is calculated as the lowest max-age among all requested fields (including composed fields).
Examples:
//1. Operators have max-age 1 year
/?query=
echo(Hello world!)
//2. Most fields have max-age 1 hour
/?query=
echo(Hello world!)|
posts.
title
//3. Composed fields also supported
/?query=
echo(posts())
//4. "time" field has max-age 0
/?query=
time
//5. To not cache a response:
//a. Add field "time"
/?query=
time|
echo(Hello world!)|
posts.
title
//b. Add <cacheControl(maxAge:0)>
/?query=
echo(Hello world!)|
posts.
title<cacheControl(maxAge:0)>Fields can be satisfied by many resolvers.
In the example below, field excerpt does not normally support field arg length, however a new resolver adds support for this field arg, and it is enabled by passing field arg branch:experimental:
//1. Standard behaviour
/?query=
posts.
excerpt
//2. New feature not yet available
/?query=
posts.
excerpt(length:30)
//3. New feature available under
// experimental branch
/?query=
posts.
excerpt(
length:30,
branch:experimental
)Advantages:
Fields can be made available only if user is logged-in, or has a specific role. When the validation fails, the schema can be set, by configuration, to either show an error message or hide the field, as to behave in public or private mode, depending on the user.
For instance, the following query will give an error message, since you, dear reader, are not logged-in:
/?query=
me.
nameO(n), where n is #types)The “N+1 problem” is completely avoided already by architectural design. It doesn't matter how many levels deep the graph is, it will resolve fast.
Example of a deeply-nested query:
/?query=
posts.
author.
posts.
comments.
author.
id|
name|
posts.
id|
title|
url|
tags.
id|
slugDirectives receive all their affected objects and fields together, for a single execution.
In the examples below, the Google Translate API is called the minimum possible amount of times to execute multiple translations:
// The Google Translate API is called once,
// containing 10 pieces of text to translate:
// 2 fields (title and excerpt) for 5 posts
/?query=
posts(limit:5).
--props|
--props@spanish<
translate(en,es)
>&
props=
title|
excerpt
// Here there are 3 calls to the API, one for
// every language (Spanish, French and German),
// 10 strings each, all calls are concurrent
/?query=
posts(limit:5).
--props|
--props@spanish<
translate(en,es)
>|
--props@french<
translate(en,fr)
>|
--props@german<
translate(en,de)
>&
props=
title|
excerptExample calling the Google Translate API from the back-end, as coded within directive <translate>:
//1. <translate> calls the Google Translate API
/?query=
posts(limit:5).
title|
title@spanish<
translate(en,es)
>
//2. Translate to Spanish and back to English
/?query=
posts(limit:5).
title|
title@translateAndBack<
translate(en,es),
translate(es,en)
>
//3. Change the provider through arguments
// (link gives error: Azure is not implemented)
/?query=
posts(limit:5).
title|
title@spanish<
translate(en,es,provider:azure)
>Example accessing an external API from the query itself:
/?query=
echo([
usd: [
bitcoin: extract(
getJSON("https://api.cryptonator.com/api/ticker/btc-usd"),
ticker.price
),
ethereum: extract(
getJSON("https://api.cryptonator.com/api/ticker/eth-usd"),
ticker.price
)
],
euro: [
bitcoin: extract(
getJSON("https://api.cryptonator.com/api/ticker/btc-eur"),
ticker.price
),
ethereum: extract(
getJSON("https://api.cryptonator.com/api/ticker/eth-eur"),
ticker.price
)
]
])@cryptoPricesThe last query from the examples below accesses, extracts and manipulates data from an external API, and then uses this result to accesse yet another external API:
//1. Get data from a REST endpoint
/?query=
getJSON("https://newapi.getpop.org/wp-json/newsletter/v1/subscriptions")@userEmailLangList
//2. Access and manipulate the data
/?query=
extract(
getJSON("https://newapi.getpop.org/wp-json/newsletter/v1/subscriptions"),
email
)@userEmailList
//3. Convert the data into an input to another system
/?query=
getJSON(
sprintf(
"https://newapi.getpop.org/users/api/rest/?query=name|email%26emails[]=%s",
[arrayJoin(
extract(
getJSON("https://newapi.getpop.org/wp-json/newsletter/v1/subscriptions"),
email
),
"%26emails[]="
)]
)
)@userNameEmailListThe example below defines and accesses a list of all services required by the application:
/?query=
echo([
github: "https://api.github.com/repos/GatoGraphQL/GatoGraphQL",
weather: "https://api.weather.gov/zones/forecast/MOZ028/forecast",
photos: "https://picsum.photos/v2/list"
])@meshServices|
getAsyncJSON(getSelfProp(%self%, meshServices))@meshServiceData|
echo([
weatherForecast: extract(
getSelfProp(%self%, meshServiceData),
weather.periods
),
photoGalleryURLs: extract(
getSelfProp(%self%, meshServiceData),
photos.url
),
githubMeta: echo([
description: extract(
getSelfProp(%self%, meshServiceData),
github.description
),
starCount: extract(
getSelfProp(%self%, meshServiceData),
github.stargazers_count
)
])
])@contentMeshUse custom fields to expose your data and create a single, comprehensive, unified graph.
The example below implements the same logic as the case above, however coding the logic through fields (instead of through the query):
// 1. Inspect services
/?query=
meshServices
// 2. Retrieve data
/?query=
meshServiceData
// 3. Process data
/?query=
contentMesh
// 4. Customize data
/?query=
contentMesh(
githubRepo: "getpop/api-graphql",
weatherZone: AKZ017,
photoPage: 3
)@contentMeshQuery sections of any size and shape can be stored in the server. It is like the persisted queries mechanism provided by GraphQL, but more granular: different persisted fragments can be added to the query, or a single fragment can itself be the query.
The example below demonstrates, once again, the same logic from the example above, but coded and stored as persisted fields:
// 1. Save services
/?query=
--meshServices
// 2. Retrieve data
/?query=
--meshServiceData
// 3. Process data
/?query=
--contentMesh
// 4. Customize data
/?
githubRepo=getpop/api-graphql&
weatherZone=AKZ017&
photoPage=3&
query=
--contentMeshGet the best from both GraphQL and REST: query resources based on endpoint, with no under/overfetching.
// Query data for a single resource
{single-post-url}/api/rest/?query=
id|
title|
author.
id|
name
// Query data for a set of resources
{post-list-url}/api/rest/?query=
id|
title|
author.
id|
nameReplace "/graphql" from the URL to output the data in a different format: XML or as properties, or any custom one (implementation takes very few lines of code).
// Output as XML: Replace /graphql with /xml
/api/xml/?query=
posts.
id|
title|
author.
id|
name
// Output as props: Replace /graphql with /props
/api/props/?query=
posts.
id|
title|
excerptJust by removing the "/graphql" bit from the URL, the response is normalized, making its output size greatly reduced when a same field is fetched multiple times.
/api/?query=
posts.
author.
posts.
comments.
author.
id|
name|
posts.
id|
title|
urlCompare the output of the query in PoP native format:
...with the same output in GraphQL format:
Issues are handled differently depending on their severity:
//1. Deprecated fields
/?query=
posts.
title|
published
//2. Schema warning
/?query=
posts(limit:3.5).
title
//3. Database warning
/?query=
users.
posts(limit:name()).
title
//4. Query error
/?query=
posts.
id[book](key:value)
//5. Schema error
/?query=
posts.
non-existant-field|
is-status(
status:non-existant-value
)When an argument has its type declared in the schema, its inputs will be casted to the type. If the input and the type are incompatible, it ignores setting the input and throws a warning.
/?query=
posts(limit:3.5).
titleIf a field or directive fails and it is input to another field, this one may also fail.
/?query=
post(divide(a,4)).
titleIssues contain the path to the composed field or directive were it was produced.
/?query=
echo([hola,chau])<
forEach<
translate(notexisting:prop)
>
>Any informative piece of information can be logged (enabled/disabled through configuration).
/?
actions[]=show-logs&
postId=1&
query=
post($postId).
title|
date(d/m/Y)
To celebrate this personal milestone, starting from today I'll publish a series of blog posts sharing my experience, as to encourage everyone to also dare try (I don't necessarily mean to write articles for some prestigious online magazine, but for your own personal blog too, as I'm doing right now).
My topic for today is: Why? Why would you want to publish your writings?
There are many many compelling reasons, but the main ones, at least for me, are the following ones.
If you are like me, most likely than not, you have something that could benefit from being publicized within your community. For instance, if you are a freelance designer or developer, showing your work and line of thinking will help you get new clients. If your agency builds websites, demonstrating that fancy-looking layout that you designed will portray your agency as being stylish and playful, or explaining how to write coherent copytext will establish your agency as a reliable provider of corporate solutions. If you sell services that tackle a need by the community, and you teach the ingredients that make your services work, you may get new customers. If you have an open source project, and you elucidate how it deals with a specific problem that someone in the community is experiencing, you may get contributors for your project. And so on and on.
(In my case, it is PoP within the web community and, more recently, GraphQL API for PoP within the API-design community... sorry for this un-invited ad, shame on me!)
Now, you can make the whatever-it-is-you-want-to-publicize the topic of your article, but you don't need to: Just by having your name out there you are already getting publicity. If your article is compelling, people will want to find out more about you, who you are and what you do. As an example concerning me, when typing "Leonardo Losoviz" in the input in Google, it suggests to autocomplete it as "leonardo losoviz pop", evidencing how people are looking for my project associated to my name.
In some situations, publishing an article out there is not just a nice-to-have, but it could be the deciding factor to attract the interest from the community and, ultimately, attain your goals (this is the case, for instance, for getting contributors for your open source project).
Online magazines not only host your content but attempt to make it go viral too. In their guide How to Spread The Word About Your Code, Peter Cooper and Robert Nyman recommend:
A single tweet from @smashingmag could drive thousands of visitors your way, so consider tweeting them, and other similar accounts, when you have something relevant.
Publishing on an online magazine, and also on your personal blog, gives you plenty of face, which increases your chances of getting a job or being accepted to speak in tech conferences.
Several online magazines (including Smashing) pay for each contributed article. However, beware! You should think twice before writing articles if you do it just for the money, because it may not be worth it. Taking into account the time required by all activities involved when writing an article (jotting down ideas, submitting a proposal, writing the article, sending it for review, editing it to incorporate feedback, replying to comments, and others), depending on your particular case, the money may not justify the expense of time.
For instance, if the article requires 7 days of work (which is a reasonable estimate when the article is comprehensive, or involves plenty of research), and if you're working as a software engineer for some Silicon Valley company for which you get paid handsomely, then the money you will make from the article will quite likely not justify the amount of time put into it.
Conclusion: Do it for the art of it, and for sharing with the community. Not for the money.
After posting a random thought on Twitter and seeing it retweeted, or after uploading a pic of your chicken rice on Instagram and having people comment how delicious it looks, you will most likely experience that pleasurable sensation of instant gratification, originating from being acknowledged by not only friends and acquaintances but also by strangers. We are social animals, and sharing content with each other, either face-to-face or through online sites and social networks, is part of who we are. Publishing an article online produces those sensations on me (and I'm pretty sure it will on you too): A smile crops along my face and my mood for the rest of the day becomes better. It just feels good.
The sensation is more pronounced when your content is truly appreciated by the target community and you are sincerely thanked for it. For instance, an article of mine received the comment below, making my day:
Until my next blog post... See you, and thanks for reading! (No comments on my blog yet 😢 If you want to leave a comment, or simply share this blog post with your friends, please use this Twitter link.)
👋
]]>Oh boy, that was a lot of work, but sure it was all worth it: PoP can now run pretty much with any PHP-based framework, including Symfony and Laravel!
Yay!!!!!
🤘🏻
I have recently published an extensive account of it, split into 2 parts, for Smashing Magazine. If you need to:
👉 Migrate your WordPress PHP code to other platforms
👉 Or re-use your Gutenblock PHP code for Laravel, Drupal
👉 Or make your application code more understandable, dealing only with business logic
👉 Or you are simply interested to know how the abstraction is accomplished
...then check my articles on Smashing:
Part 1: Abstracting WordPress code to reuse with other CMSs - Concepts
Part 2: Abstracting WordPress code to reuse with other CMSs - Implementation
Enjoy!
]]>Cache-Control header.
(Really, GraphQL, how comes you still don't support it? Why do you keep re-inventing the wheel?)
It sends a Cache-Control header with a max-age value, or no-store if the response must not be cached.
The beauty of the implementation for PoP is that every field can have a different max-age configuration, and the response will automatically calculate the lowest max-age from all required fields. And it involves very few lines of code: Just decide how much time to cache each field and add it to the configuration, and that's it, chill.
Sure! Here I add several examples. Please click on the links below, and inspect the response headers using Chrome or Firefox's developer tools' Network tab.
Operators have a max-age of 1 year:
/?query=
echo(Hello world!)By default, fields have a max-age of 1 hour:
/?query=
echo(Hello world!)|
posts.
titleComposed fields are also taken into account when computing the lowest max-age:
/?query=
echo(posts())"time" field is not to be cached (max-age: 0):
/?query=
timeWays to not cache a response:
a. Add field "time" to the query:
/?query=
time|
echo(Hello world!)|
posts.
titleb. Override the default maxAge configuration for a field, by adding argument maxAge: 0 to directive <cacheControl>:
/?query=
echo(Hello world!)|
posts.
title<cacheControl(maxAge:0)>Time to celebrate!!! 🥳

I have listed down all the features that I have implemented for the PoP API, an implementation of GraphQL that gets rid of the SDL (Schema Definition Language) completely, and extracts and generates the schema from the data model defined in the application code. It may sound difficult, but it's actually so easy: The developer doesn't need to do much! Everything pretty much just works!
If you want to find out what I'm talking about, please check the slides (if they bore you, just skip to slide #24 and check the features... I promise that will be fun):
If after checking these slides you want to find out a bit more, please read my previous blog post, in which I give a step-by-step explanation of how a rather complex use case is resolved with a single query. It's a bit long, but hopefully it will be worth your time.
Let me know how it goes :)
🙌
]]>You want to create an automated email-sending service to distribute your blog posts. All the data comes from 3 separate sources:
email and language fields) to the newsletter, provided by Mailchimp.email and name fields, provided by company's CRM.The email needs to be customized for each person:
The service needs to be flexible, allowing to select the post(s) to send:
The service will be accessed by 2 different kinds of stakeholders:
Your requirements change over time, so the service will ocassionally need to implement new features. However, you do not have the budget to employ a permanent back-end developer to maintain the service in the long-term. Hence, adding new features to the service must not involve custom code (eg: providing new fields into the API).
Finally, the team members implementing the service work remotely and from different timezones, so you need to minimize their need for interaction.
Our service will follow the following steps:
email and language fieldsname field, fetching it from the second API endpoint by using the common email field as ID.By now, we will have the all the user data consolidated in a single list, containing fields name, email and language. Let's continue.
content and dateBy now, in addition to the user data, we will also have the post data, translated to all required languages. Next, we need to craft the customized email content for each user.
emailContent containing:
a. The greeting message "Hi {name}, this is our our blog post from {date}", translated to the user's language
b. The blog post content that had been translated to the user's languageBy now, we have all the data: Rows of email and emailContent fields. We can finally send the email.
Before we start the implementation of the use case, I will explain a few concepts particular to PoP.
While the standard GraphQL sends the query contained in the body of the request, PoP sends it as a URL parameter. This has the following advantages:
?query=...The syntax used in PoP is a re-imagining of the GraphQL syntax, supporting all the required elements (field names, arguments, variables, aliases, fragments and directives), however designed to be easy to both read and write in a single line, so the developer can already code the query in the browser without depending on special tooling.
It looks like this:
?query=query1,query2,query3&variable1=value&fragment1=fragmentQueryEach query has this shape:
fieldName(fieldArgs)@alias<fieldDirective(directiveArgs)>To make it clear to visualize, the query can be split into several lines:
fieldName(
fieldArgs
)@alias<
fieldDirective(
directiveArgs
)
>Note 1:
Firefox already handles the multi-line query: Copy/pasting it into the URL bar works perfectly. Chrome and Safari, though, require to strip all the whitespaces and line returns before pasting the query into the URL bar.(Conclusion: use Firefox!)
Note 2:
The syntax is described in detail in its GitHub repo. I will keep explaining how it works below, while implementing the use case.
Standard operations, such as not, or, and, if, equals, isNull, sprintf and many others, are supported as fields:
1. ?query=not(true)
2. ?query=or([1,0])
3. ?query=and([1,0])
4. ?query=if(true, Show this text, Hide this text)
5. ?query=equals(first text, second text)
6. ?query=isNull(),isNull(something)
7. ?query=sprintf(%s API is %s, [PoP, cool])[View query results: query #1, query #2, query #3, query #4, query #5, query #6, query #7]
Arguments passed to a field can receive other fields or operators as input.
?query=
posts.
if (
hasComments(),
sprintf(
"Post with ID %s has %s comment(s) and title '%s'",
[
id(),
commentsCount(),
title()
]
),
sprintf(
"Post with ID %s, created on %s, has no comments",
[
id(),
date(d/m/Y)
]
)
)@postDescA directive can modify the behaviour of another directive. Values can be passed from one to another through "expressions": special variables set by each directive, wrapped with %...%.
For instance, in the example below, directive <forEach> iterates through all the items in an array, passing each of them to its composed directive <applyFunction> through expression %value%.
echo([
[banana, apple],
[strawberry, grape, melon]
])@fruitJoin<
forEach<
applyFunction(
function: arrayJoin,
addArguments: [
array: %value%,
separator: "---"
]
)
>
>Time to implement the query! I promise this is going to be fun (at least, I certainly enjoyed doing it). Along the way I will explain how/why it works.
Let's start.
Note:
At any time, you can review the documentation for the fields/directives employed by querying the fullSchema field.
We can query field posts to find the latest published blog post:
posts(
limit:1,
order:date|DESC
).
id|
title|
urlNote 1:
Use,to separate field arguments, each of them inkey:valueformat
Note 2:
Use.to fetch nested properties from the object
Note 3:
Use|to fetch several fields from an object
This query retrieves an array of posts. To operate with a single post, we can better use field post, which receives the ID by argument:
post(
id:1
).
id|
title|
urlFields argument names are optional. The query above is similar to the one below, which skips fieldArg name "id":
post(1).
id|
title|
urlWe can pass the ID through a variable, which is resolved through a URL parameter under the variable name. For the query below, we add param postId=1 to the URL:
post($postId).
id|
title|
urlNote:
Use$to define a variable
Finally, we add an alias to make the response more compact:
post($postId)@post.
id|
title|
urlNote:
Use@to define an alias
The previous queries were demonstrating how to fetch data for the post. Now that we know, let's fetch the data needed for our use case: the content and date fields:
post($postId)@post.
content|
date(d/m/Y)@dateNote:
Use[...]to define an array and,to separate its items. The format for each item is eitherkey:valueorvalue(making the key numeric)
To fetch the list of newsletter subscribers from a REST endpoint, we can use field getJSON and specify the URL:
getJSON("https://newapi.getpop.org/wp-json/newsletter/v1/subscriptions")@userListThe previous list contains pairs of email and lang fields. Next, we calculate the list of unique languages, as to translate the blog post to all those languages. This task will be composed of two steps.
First, we extract the field lang from the array through field extract (which takes an array and a path):
getJSON("https://newapi.getpop.org/wp-json/newsletter/v1/subscriptions")@userList|
extract(
getSelfProp(%self%, userList),
lang
)Note:
Expression%self%contains an object which has a pointer to all data retrieved for the current object. Accessed through functiongetSelfProp, it enables to access this data, under the property name or alias under which it was stored.
Then, we apply operator arrayUnique, and assign the results under alias userLangs:
getJSON("https://newapi.getpop.org/wp-json/newsletter/v1/subscriptions")@userList|
arrayUnique(
extract(
getSelfProp(%self%, userList),
lang
)
)@userLangsSo far, we have a list of pairs of email and lang fields stored under property userList. Next, using email as the common identifier for the data, we query the REST endpoint from the CRM to fetch the remaining user information: the name field. This task is composed of several steps.
First, we extract the list of all emails from userList, and place them under userEmails:
extract(
getSelfProp(%self%, userList),
email
)@userEmailsOur CRM exposes a REST endpoint which allows to filter users by email, like this:
/users/api/rest/?emails[]=email1&emails[]=email2&...Then, we must generate the endpoint URL by converting the array of emails into a string with the right format, and then executing getJSON on this URL. Let's do that.
To generate the URL, we use a combination of sprintf and arrayJoin:
sprintf(
"https://newapi.getpop.org/users/api/rest/?query=name|email%26emails[]=%s",
[arrayJoin(
getSelfProp(%self%, userEmails),
"%26emails[]="
)]
)Note 1:
The string can't have character"&"in it, or it will create trouble when appending it in the URL param. Instead, we must use its code"%26"
Note 2:
The REST endpoint used for this example is also satisfied by the PoP API, which combines features of both REST and GraphQL at the same time (eg: the queried resources are/users/, and we avoid overfetching by passing?query=name|email)
Having generated the URL, we execute getJSON on it:
getJSON(
sprintf(
"https://newapi.getpop.org/users/api/rest/?query=name|email%26emails[]=%s",
[arrayJoin(
getSelfProp(%self%,userEmails),
"%26emails[]="
)]
)
)Finally, we must combine the 2 lists into one, generating a new list containing all user fields: name, email and lang. To achieve this, we use function arrayFill, which, given 2 arrays, returns an array containing the entries from each of them where the index (in this case, property email) is the same, and we save the results under property userData:
arrayFill(
getJSON(
sprintf(
"https://newapi.getpop.org/users/api/rest/?query=name|email%26emails[]=%s",
[arrayJoin(
getSelfProp(%self%, userEmails),
"%26emails[]="
)]
)
),
getSelfProp(%self%, userList),
email
)@userDataBy now we have collected the post data, saved under properties content and date, and all the user data, saved under property userData. It is time to mix these pieces of data together, for which we need to have all data at the same level. However, if we pay attention to the latest query, we can notice that they are under 2 different paths:
userData is under / (root)content and date are under /post/Hence, we must either move userData down to the post level, or move content and date up to the root level. Due to PoP's graph dataloading architecture, only the latter option is feasible. The reason is a bit difficult to explain in words, but I'll try my best. (It would be much better to show the process in images, but I'm not great at design in any case.)
(This will be a bit technical. Apologies in advance.)
When resolving the query to load data, the dataloader processes all elements from a same entity all at the same time, as to load all their data in a single query and completely avoiding the N+1 problem. (Indeed, PoP's dataloading mechanism has linear time complexity, or O(n), based on the number of nodes in the graph. That's why it is so fast to load data, even for deeply nested graphs.) Then, let's imagine that we have the following query:
posts.
title|
author.
nameLet's say this query returns 10 posts and, for each post, it retrieves its author, and some authors have 2 or more posts, so that the query retrieves 10 posts but only 4 unique authors. The dataloading mechanism will first process all 10 posts, fetching all their required data (properties title and author), and then it will fetch all data for all 4 authors (property name).
If posts with IDs 1 and 2 both have author with ID 5, and we copy a property downwards in the graph, post 1 will first copy its properties down to author 5, then immediately post 2 will copy its own properties down to author 5, overriding the properties set by post 1. By the time the dataloading mechanism reaches the users level, author 5 will only have the data from posts 2. This situation could be avoided by copying the properties the post ID in the user object, as to not override previous values. However, while the post entity knows that it is loading data for its author, the author entity doesn't know who loaded it (the graph direction is only top-to-bottom). Hence, the post entiy can fetch properties from the author entity and store them under theauthor ID (which the post knows about), but the other way around doesn't work.
That's why we can only copy properties upwards. In this case, the post's content and date properties must be copied upwards, to the root.
We can now go back to the query.
To copy the content and date properties upwards to the root level, we use directive <copyRelationalResults>. This directive is applied on the root entity, and it receives these inputs:
post($postId)@postcontent and datepostContent and postDateself.
post($postId)@post<
copyRelationalResults(
[content, date],
[postContent, postDate]
)
>[View query results: GraphQL output, PoP native output]
That this works is not evident at all. Moreover, you need to click on link PoP native output to see the results, and appreciate that the data was indeed copied one level up. The other link, GraphQL output, would seem to not work... it also does, but the results are not being output!
To understand why this is so, I'll need to take several detours, to explain how data is loaded (once again) and how directives work.
(Please be aware: the following few sections, until tackling the translation challenge again, are dense and technical. If you dare read them, good for you! If you don't, don't worry, just skip them, you may come back to them later...)
Directives are sheer power: They can affect execution of the query in any desired way. They are as close to the bare metal of the dataloading engine as possible. They have access to all previously loaded data and can modify it, remove it, etc.
Directives help regulate the lifecycle of loading data in the API, by validating and resolving the fields on the objects and adding these results on a directory with all results from all objects, from which the graph is drawn.
The dataloading engine relies on the following special directives to implement core functionality:
<setSelfAsExpression>, which defines the "expression" %self% which allows to retrieve previously loaded data<validate>, which validates that the provided data matches against its definition on the schema and, if it doesn't, removes it and shows a error message<resolveValueAndMerge>: it resolves all the fields in the query and merges their response into the final database objectThese 3 directives are executed at the beginning of their own slots:
<setSelfAsExpression><validate><resolveValueAndMerge>Every directive we create must indicate in which from these 3 slots it must be placed and executed. For instance, directives <skip> and <include> (mandatory ones in GraphQL) must be placed in the "Middle" slot, that is after fields are validated but before resolved; directive <copyRelationalProperties> must be placed in the "Back" slot, since it requires the data to be resolved before it can copy it somewhere else.
Let's examine the query above together with the previous query bit that loads properties content and date:
post($postId)@post.
content|
date(d/m/Y)@date,
self.
post($postId)@post<
copyRelationalResults(
[content, date],
[postContent, postDate]
)
>[View query results: PoP native output]
We can see that these 2 queries are separated using , instead of |, and that there is an entity self after which we repeat the same field post($postId)@post, and only then we apply directive <copyRelationalResults>. Why is this so?
Field self is an identity field: It returns the same object currently being operated on. In this case, it returns once again the entity root. (Doing self returns the root object, doing post.self returns the same post object, doing post.author.self returns the user object, and so on.)
As I mentioned before, the dataloader loads data in stages, in which all data for a same type of entity (all posts, all users, etc) is fetched all together. Using , to separate a query makes it start iterating from the root all over again. Then, when processing this query...
post,
self.post...the entites being handled by the dataloader are these ones, in this exact order: root (the first one, always), posts (loaded by query posts, before the ,), root (the first one again, after ,), root again (loaded by doing self on the root object) and then posts again (by doing self.post).
As can be seen, the self field then enables to go back to an already loaded object, and keep loading properties on it. As such, it allows to delay loading certain data until a later iteration of the dataloader, to make sure a certain condition is satisfied.
That is exactly why we need it: Directive <copyRelationalResults> copies a property one level up, but it is applied on the root object and, by the time it is executed, the properties to copy must exist on the post object. Hence the iteration: root loads the post, the post loads its properties, then back to root copies the properties from the post to itself.
We saw in the query above...
self.
post($postId)@post<
copyRelationalResults(
[content, date],
[postContent, postDate]
)
>... that we need to view the query results in PoP native output to see that the directive <copyRelationalResults> worked, and that the GraphQL output doesn't mirror the changes. What is going on?
First of all: the PoP API does NOT use a graph to represent the data model. Instead, it uses components, as I have explained in this article.
However (and this is the fact that makes the magic happen) a graph does naturally arise from the relationships among the database entities defined through components, which I described in my article. Hence, the graph can be easily generated from the component-based architecture of the API, and the GraphQL implementation is simply an application among many. For instance, if replacing the /graphql bit in the URL with /rest, we obtain the equivalent REST endpoint (as demonstrated for the REST API endpoint to fetch the user data); if we replace it with /xml, we access the data in XML format (example).
The real, underlying data structure in PoP is simply a set of relationships across database objects, which matches directly with how an SQL database works: Tables containing rows of data entries, and relationships among entities defined through IDs. That is exactly what you see when you remove the /graphql bit from the URL, from any URL (example). That's the PoP native format. Looking at is like looking at the code in the matrix.

The developer needs not define schemas, and certainly need not deal with the SDL. Instead, it's all about defining the relationships among the different database entities in the application, which will quite likely already exist! Just by replicating the relationships already defined in the data model, we can obtain the GraphQL schema for free, automatically generated from the component model itself, and visualized by querying the fullSchema field.
Finally, we can provide an explanation of why the query results in PoP native output for directive <copyRelationalResults> are shown, but not in the GraphQL output: The PoP native format displays all the data it has accumulated, thereby there it is. The GraphQL format, though, doesn't show it because the properties under which the data are copied to, postContent and postDate, are not being queried. If we do (adding 2 levels of self to make sure we query the data after it has been copied), the data then does appear in the response:
self.
post($postId)@post<
copyRelationalResults(
[content, date],
[postContent, postDate]
)
>,
self.
self.
getSelfProp(%self%, postContent)|
getSelfProp(%self%, postDate)Note:
In the response for the GraphQL query above, properties appear under path/self.self, and not directly under/. However, they are the same entityroot(selfreturns itself, on whichever object it is applied to). This is, once again, easier to visualize in the PoP native format, removing the/graphqlbit from the URL
Oh boy, that was quite a ride! But now we're finally back to business... Let's continue implementing the query!
We have by now properties postContent, postDate and userData all loaded at the root level, which is all the information we need to work with. From now on, being at the root level we can execute all the operators and directives necessary to accomplish our goals.
Next, we apply directive <translate> on postContent, which will call the Google Translate API to translate the text. Why is it a directive, instead of an operator? Let's take a quick detour to explain the differences between these two.
When coding a query, it may be sometimes unclear what is better, if to use an operator or use a directive. After all, the two of them can both execute functionality (such as sending an email, or translating a piece of text). For instance, we could do either posts.translate(title) (operator) or posts.title<translate> (directive). So, when to use one or the other?
When executing functionality, the main difference between these 2 is the following:
An operator is a field. A field computes a value from a single object; every field is executed independently of each other field, and it is executed once per object. For instance, for the following query...
post.
title... the field title is executed once on each post object. If there are 10 posts, then title is executed 10 times, once in each. And they see no history: given a set of inputs, they just return their output. They don't have really a lot of logic, or complexity.
Since operators are fields, we have the same situation: For the following query...
post.
sprintf(
"Post title is",
[title()]
)... the sprintf operator is executed once in each title property, which is executed 10 times, once per post, all independently from each other, and oblivious of each other.
Directives work in a different way: They are executed just once on the set of affected objects, and on the set of affected properties for each object, and they can modify the value of these properties for each of the objects. For instance, for the following query:
posts.
title<
applyFunction(...)
>|
content<
applyFunction(...)
>... the directive <applyFunction> will be executed only once (even if it appears twice in the query, once for each field), receiving a set of posts and properties title and content for each post.
Hence, we must use directives when:
<sendByEmail> directive sending 10 emails at once is more effective than a sendByEmail() operator sending 10 emails independently, and making 10 SMTP connections; a <translate> directive can make a single call to the translation API to translate all strings at once, which is more efficient than calling translate() on 10 strings which will make 10 calls to the translation API.Now we know why we are doing content<translate> instead of translate(content). Let's continue.
The following query takes care of translating the post content to all the different unique languages gathered earlier on from the user data:
self.
self.
getSelfProp(%self%, postContent)@postContent<
translate(
from:en,
to:arrayDiff([
getSelfProp(%self%, userLangs),
[en]
])
)
>[View query results: GraphQL output (changes not yet visible), PoP native output (changes already there)]
We can see that the <translate> directive takes 2 inputs through directive arguments: the from language (English) and the to language or array of languages. Since we want to translate to many languages, we provide this list, but first removing English from the list (through operator arrayDiff). Otherwise, the Google Translate API throws an error when attempting to translate from English to English.
The <translate> directive did not override the original property on the object, but instead created additional ones which append the language code. Hence, by now, we have the following entries with the post content: postContent (original in English), postContent-es (Spanish), postContent-fr (French) and postContent-de (German). To homogenize it, we rename property postContent to postContent-en through directive <renameProperty>:
self.
self.
getSelfProp(%self%,postContent)@postContent<
translate(
from:en,
to:arrayDiff([
getSelfProp(%self%, userLangs),
[en]
])
),
renameProperty(postContent-en)
>[View query results: GraphQL output (changes not yet visible), PoP native output (changes already there)]
Note:
When applying more than 1 directive to the same affected objects and fields, we can simply concatenate them with,in the order in which they will be executed, as in<translate(...), renameProperty(...)>.However, because a directive is executed on its selected slot from among
"Front","Middle"and"Back", only the order within the slot will always be respected. It may be that defining<directive1, directive2>will have<directive2>execute before than<directive1>if its slot is executed earlier.
By now, we have translated the post content to all different unique languages. Next, let's add the corresponding translation for each user, creating a new property userPostData.
To achieve this, we will make use of directive <forEach> which iterates over an array, and passes each array item to its composed directive <applyFunction> through expression %value%. This directive then executes function arrayAddItem on each item, which adds an element (the translated post content) to an array (the user data). In order to deduce the selected language, it uses functions extract to get the lang property from the user data array, then injects it into sprintf to generate the corresponding postContent-languagecode property, which is then retrieved from the current object (the root) and placed under property postContent on the array. All field arguments needed by function arrayAddItem are injected by the directive <applyFunction> on runtime through the array defined in argument addArguments.
self.
self.
getSelfProp(%self%, userData)@userPostData<
forEach<
applyFunction(
function: arrayAddItem(
array: [],
value: ""
),
addArguments: [
key: postContent,
array: %value%,
value: getSelfProp(
%self%,
sprintf(
postContent-%s,
[extract(%value%,lang)]
)
)
]
)
>Note:
FunctionarrayAddItemstill initially defines field argumentsarrayandvalue, even if initialized with empty values. This must be done because these arguments are set as mandatory in the schema definition, so if they are not present, it is considered a schema validation error and this section of the query is ignored.
Let's next deal with the greeting message, which must be translated to the user's language. Initially the message is a placeholder, and we customize it through the user name field and the post date field. Only then we can do the translation, as to help Google Translate do a better job at it (translating "Hi Leo!" should produce better results than translating "Hi %s!")
We first add the message into the array containing all other user data under property header, and already customizing it with the user data. The logic is similar as in the previous query, for which we also use directive <applyFunction>, which can be executed within the same iteration of the previous <forEach> directive:
self.
self.
getSelfProp(%self%, userData)@userPostData<
forEach<
applyFunction(
function: arrayAddItem(
array: [],
value: ""
),
addArguments: [
key: header,
array: %value%,
value: sprintf(
string: "<p>Hi %s, we published this post on %s, enjoy!</p>",
values: [
extract(%value%, name),
getSelfProp(%self%, postDate)
]
)
]
)
>
>Finally, we translate the message to the user's language. To do this, we use directive <forEach> to iterate on all array items whose lang field is "en" (for English), since we don't want to translate those. This is accomplished through the filter condition passed through argument if. Then, each array item is passed to the composed directive <advancePointerInArray>, which can navigate the inner structure of the array and position itself on the property that needs be translated: header.
Finally the element is passed to the next composed directive, <translate>, which receives a string of arrays to translate as its affected fields, and an array of languages to translate to passed through expression toLang (which we create on-the-fly just for this purpose of communicating data across directives), and by setting argument oneLanguagePerField to true and override to true the directive knows to match each element on these 2 arrays to do the translation and place the result back on the original property.
self.
self.
self.
getSelfProp(%self%, userPostData)@translatedUserPostProps<
forEach(
if:not(equals(extract(%value%,lang),en))
)<
advancePointerInArray(
path: header,
appendExpressions: [
toLang:extract(%value%,lang)
]
)<
translate(
from: en,
to: %toLang%,
oneLanguagePerField: true,
override: true
)
>
>
>We are almost there! All that there is left to do is to generate the content for all the emails to send: arrays containing properties content, to and subject, and then this array is passed to directive <sendByEmail> which, voilà, does what it must do! (Or actually not: Since I don't like spam, the email sending is actually disabled... I just print the email data instead)
self.
self.
self.
self.
getSelfProp(%self%,translatedUserPostProps)@emails<
forEach<
applyFunction(
function: arrayAddItem(
array: [],
value: []
),
addArguments: [
key: content,
array: %value%,
value: concat([
extract(%value%,header),
extract(%value%,postContent)
])
]
),
applyFunction(
function: arrayAddItem(
array: [],
value: []
),
addArguments: [
key: to,
array: %value%,
value: extract(%value%,email)
]
),
applyFunction(
function: arrayAddItem(
array: [],
value: []
),
addArguments: [
key: subject,
array: %value%,
value: "PoP API example :)"
]
),
sendByEmail
>
>We have everything we need! Let's get it all together into the one, final, monstruous, magnificent query:
post($postId)@post.
content|
date(d/m/Y)@date,
getJSON("https://newapi.getpop.org/wp-json/newsletter/v1/subscriptions")@userList|
arrayUnique(
extract(
getSelfProp(%self%, userList),
lang
)
)@userLangs|
extract(
getSelfProp(%self%, userList),
email
)@userEmails|
arrayFill(
getJSON(
sprintf(
"https://newapi.getpop.org/users/api/rest/?query=name|email%26emails[]=%s",
[arrayJoin(
getSelfProp(%self%, userEmails),
"%26emails[]="
)]
)
),
getSelfProp(%self%, userList),
email
)@userData,
self.
post($postId)@post<
copyRelationalResults(
[content, date],
[postContent, postDate]
)
>|
self.
getSelfProp(%self%, postContent)@postContent<
translate(
from: en,
to: arrayDiff([
getSelfProp(%self%, userLangs),
[en]
])
),
renameProperty(postContent-en)
>|
getSelfProp(%self%, userData)@userPostData<
forEach<
applyFunction(
function: arrayAddItem(
array: [],
value: ""
),
addArguments: [
key: postContent,
array: %value%,
value: getSelfProp(
%self%,
sprintf(
postContent-%s,
[extract(%value%, lang)]
)
)
]
),
applyFunction(
function: arrayAddItem(
array: [],
value: ""
),
addArguments: [
key: header,
array: %value%,
value: sprintf(
string: "<p>Hi %s, we published this post on %s, enjoy!</p>",
values: [
extract(%value%, name),
getSelfProp(%self%, postDate)
]
)
]
)
>
>|
self.
getSelfProp(%self%, userPostData)@translatedUserPostProps<
forEach(
if: not(
equals(
extract(%value%, lang),
en
)
)
)<
advancePointerInArray(
path: header,
appendExpressions: [
toLang: extract(%value%, lang)
]
)<
translate(
from: en,
to: %toLang%,
oneLanguagePerField: true,
override: true
)
>
>
>|
self.
getSelfProp(%self%,translatedUserPostProps)@emails<
forEach<
applyFunction(
function: arrayAddItem(
array: [],
value: []
),
addArguments: [
key: content,
array: %value%,
value: concat([
extract(%value%, header),
extract(%value%, postContent)
])
]
),
applyFunction(
function: arrayAddItem(
array: [],
value: []
),
addArguments: [
key: to,
array: %value%,
value: extract(%value%, email)
]
),
applyFunction(
function: arrayAddItem(
array: [],
value: []
),
addArguments: [
key: subject,
array: %value%,
value: "PoP API example :)"
]
),
sendByEmail
>
>We are done now! Use case accomplished!!!!
🥳
I'm sure that if you have reached up to here, you must be tired! You certainly must not want to keep reading technical, boring code, even if were about the most shinily awesome API ever... right?
Me neither. So I will continue in another blog post to describe how this API either already deals with, or will soon, the following issues:
I hope you have enjoyed this. If so, please check out PoP (where it explains how the component model works), and the myriad of repos implementing the logic:
PoP has been implemented in PHP, it relies on Composer for installation, and it can work with most popular CMSs and frameworks (WordPress, Symfony, Laravel). It is still under heavy development, so I would advise against using it in PROD for the time being. But all code is stable, so please go ahead, download it, and play with it in your DEV environment. Fortunately, the data model in the PoP API is the existing one in the application (remember: There are no schemas!), so its introduction to an existing project can demand very low effort.
The version for WordPress is ready to install. Simply add the following packages in your composer.json file:
"require": {
"getpop/engine-wp": "dev-master",
"getpop/commentmeta-wp": "dev-master",
"getpop/comments-wp": "dev-master",
"getpop/pages-wp": "dev-master",
"getpop/postmeta-wp": "dev-master",
"getpop/posts-wp": "dev-master",
"getpop/posts-api": "dev-master",
"getpop/postmedia-wp": "dev-master",
"getpop/taxonomies-wp": "dev-master",
"getpop/taxonomymeta-wp": "dev-master",
"getpop/taxonomyquery-wp": "dev-master",
"getpop/usermeta-wp": "dev-master",
"getpop/users-wp": "dev-master",
"getpop/api-graphql": "dev-master",
"getpop/api-rest": "dev-master",
"getpop/google-translate-directive": "dev-master"
}More detailed instructions for installation can be found in this GitHub repo.
Adopters and contributors are welcome... Thanks for reading! 😀
]]>Title: Introduction to “PoP API”, a brand-new GraphQL server in PHP
Description:
“With GraphQL, you model your business domain as a graph by defining a schema; within your schema, you define different types of nodes and how they connect/relate to one another.” Through schemas, GraphQL has greatly improved the development experience as compared to REST, enabling applications to be shipped faster then ever.
However, mainly due to the limitations from a schema model, GraphQL has faced several issues that, after several years of trying, nobody has been able to solve on a conclusive manner. Among them, its security is suboptimal, since it enables malicious actors to execute Denial of Service attacks on the database server; it cannot be cached on the server, since it mainly operates through POST requests, adding complexity and processing cost to the application on the client-side; a type definition must live on a single location, making it difficult for team members to collaborate (as evidenced by the deprecation of schema stitching and the difficulty of implementing the data model in the specific way demanded by the federation approach), more often than not leading to a monolith architecture; it can become tedious to set it up on the server, since each schema must list down all of its objects' properties, leading to an overabundance of code; and executing a query with many levels of depth can become very slow, since its time complexity to resolve queries can be exponential.
Luckily, there is an alternative approach to using a schema model for representing an information graph, which does not suffer any of its disadvantages: Components! A component hierarchy can mirror the data structure from a graph, enabling us to obtain the benefits from GraphQL, while at the same time losing none of the advantages from a simple REST architecture. Picture yourself accessing the great development experience of GraphQL, but with the added server-side performance and security from REST, minus the inconvenience of having to set-up thousands of properties on the schema, and allowing the team to split the creation of the data model without any overlapping of tasks or need to set-up special tooling.
A data API based on components is the greatest kept secret... until this presentation demonstrates all about it. Join me for an enlightening journey into the power of components!
]]>The time complexity to execute queries is much lower: Whereas GraphQL's is exponential (O(2^n)), PoP's is just quadratic (or O(n^2)) in worst case, and linear (or O(n)) in average (where n is the amount of nodes in the query graph). As a consequence, executing deeply nested queries will take lower time, and the risk of Denial of Service attacks is also reduced.
Because the schema is dynamically built from a component model, it can decide to incorporate or discard different elements based on different factors or situations. As such, these use cases can be easily implemented:
Make an API that is both public and private, by enabling certain fields only if the user is logged-in, or if the user has a specific user role (such as admin)
Build a One-Graph solution for everything, creating a customizable gateway to different services (Twitter, Salesforce, Slack, Stripe, etc) from a single endpoint
Through a special directive, each field can indicate its cache-control configuration, and the request will calculate the overall cache-control based on all the requested fields:
GraphQL's schema requires a type definition to live on a single location, making it difficult for team members to collaborate, often leading to a monolith architecture, or to the need to set-up special tooling to generate the schema.
Because PoP is not based on the Schema Definition Language (or SDL), it overcomes these drawbacks, and supports:
Check out these examples:
Normal behaviour:
?query=posts.id|title|excerpt
Overriding behaviour #1 (available under the "experimental" branch):
?query=posts.id|title|excerpt(branch:experimental,length:30)
Overriding behaviour #2 (available under the "try-new-features" branch):
?query=posts(limit:2).id|title|content|content(branch:try-new-features,project:block-metadata)
Imagine that you need to implement the following functionality:
In some system, you have a REST API endpoint returning the subscribers to a newsletter: a list of email and lang fields
In another system, you have a database with user information: rows of id, email and name fields
In another system, you have blog posts
You want to send the content of a blog post in a newsletter to all your users, like this:
Hi {name},
welcome to our weekly newsletter! Our post from today:
{post-title}
{post-content}
The newsletter must be translated to the user's preferred language!
How would you do that using a standard GraphQL implementation? Would you believe me if I say that it can be resolved in only 1 line, and without implementing any custom server-side code?
🤔
I will keep you posted 🤔
]]>The inspiration for my article came from connecting the dots. One one side, after watching Karen McGrane's talk Content in a Zombie Apocalypse, I understood that it is futile to keep designing our content for a specific screen size, when this is a factor we cannot control anymore (this is indisputable since the launch of the Apple Watch). Instead, we must plan for our content to adapt itself to the medium, whichever the medium is and whichever its qualities (screen-based, audio-based, goggle-based, etc). For that, the content must be medium-agnostic, and the only way to achieve this is by "separating form from content", something that is easier said than done (as I explain in my Smashing article).
On the other side, Gutenberg! Many people in the WordPress community still seem to be bitter about it, and I understand why they are so, since it greatly increases the complexity of developing the application (React is not trivial, and it is unfair that everyone now needs to become an expert developer to accomplish things that were easy to do in the past, and for which no development experience was required). However, Gutenberg also brings plenty of new opportunities that were not possible before, and that's what keeps me motivated! In our case in particular, because it is block-based (instead of blob-based), Gutenberg makes it easy to extract all metadata from all blocks added in a post, making it feasible to implement the COPE strategy. This is wonderful news for anyone having to manage content for different platforms. How difficult is to put a process in place to handle this normally? How much easier can it become through leveraging Gutenberg?
As a proof of concept to show how well it works, I created a project which exports all the block metadata added to a post through an API: COPE with WordPress. To see it working, check out this link, which exports all metadata from this blog post.
After this implementation, something was still missing: Even though we can now access all metadata, not every piece of metadata is suitable for all mediums. For instance, if we are interacting with an iPod or with Amazon Alexa, then we're mostly interested in audio files; if we are using an Apple Watch, forget about reading text, it's all about images or video. Then, I set out to add content filtering capabilities to the API.
Unluckily, this proved impossible to implement for both REST (not feasible) and GraphQL (creating different types for all types of metadata is so verbose and cumbersome, that I gave up while trying). However, my project PoP can easily support this feature, through the GraphQL extension that transforms the application into a GraphQL server, and by adding field modifiers to filter the metadata according to the type of block, as I did for project Block Metadata for WordPress.
Check out the results of filtering metadata through the PoP API:
Thanks for reading!
]]>It sounds good, right? But, is it even possible to implement?
🤔
Yes it is!
😲
I have been recently implementing GraphQL's specification using PoP's component-based architecture, and it works like a charm! Because server-side components can represent a graph (as I have indirectly shown in my article for Smashing Magazine), these can be used instead of schemas to represent the application's data model, providing all the same features that schemas do.
Now, I can claim without a doubt or regret: Schemas are not only the foundation of GraphQL, but also its biggest liability! Because of the architecture they impose, schemas (as coded through the Schema Definition Language) limit what GraphQL can (or cannot) achieve, leading to GraphQL's biggest drawbacks: Limited server-side caching, over-complexity (schema stitching, schema federation), risk of Denial of Service attacks, and difficulty of having a decentralized team collaborate on the schema (which may lead to monolithic data models), among others.
Components can avoid all of these issues...
The result of my research is the new project GraphQL API (based on the PoP API). The implementation of the GraphQL spec is not 100% complete: Support for GraphQL's input query is currently missing (but I'm working on it and should be ready within a few weeks) and other minor differences. However, it complies with everything that makes GraphQL great, particularly retrieving the queried data and nothing more or less, and having the response reflect the shape of the query.
The API has a schema... but it is not coded by anyone! Instead, it is automatically-generated from the component model itself: Simply by coding classes following OOP principles, the application will generate the schema.
To visualize it, in addition to the standard introspection field __schema, we can query field fullSchema:
/api/graphql/?query=fullSchema
This API is natively powered by a syntax compatible with URL-based queries, which in addition to supporting all the expected features (arguments, variables, directives, etc), it also grants GraphQL superpowers, such as:
I provided several examples of these new features in my previous post 😲 Making GraphQL cacheable through a new, single-line query syntax!?.
However, if working with a new syntax makes you uncomfortable, fear not: I'm already working on building a service that converts from the 2 different syntaxes, bi-directionally. Then, it will be possible for the client to choose which syntax to use on a query-by-query basis. (For instance, if the query must be cached, then use my proposed new syntax; otherwise, use the standard one.)
Components can deliver additional features to those available in the GraphQL spec, resulting in better speed and security, enhanced team collaboration, simpler client-side and server-side code, and others. I will write about these in my upcoming blog posts.
😎
Thanks for reading!
]]>The problem is GraphQL's query, which generally spans multiple lines, and is sent to the server through the body of the request instead of through URL params. If the query could be passed through URL params instead, we could then use standard mechanisms to cache the page in the server based on its URL as a unique ID.
Sure, we could have a client-side library like Relay simply compress the query in a single line, and append it to the URL. However, the URL will be pretty much unreadable, and we won't be able to manually code it anymore, as we do with REST. So this is not a solution.
A better approach is to re-create the GraphQL syntax, attempting to support all the same elements (field arguments, variables, aliases, fragments, directives, etc), however designed to be easy to write, and easy to read and understand, in a single line, so it can be passed as a URL param.
This is what I did, and I think I might have succeeded!? The results are in this GitHub repo (check it out!), and I show several examples below... ta ta ta taaaannnnnn...
🥁
In the repo's README is the description of how each query element is coded. Hoping that the syntax is self-evident, or at least understandable enough, here I just only show some examples:
Simple query:
/?query=posts.id|title|url
Nested query:
/?query=posts.comments.author.posts.id|title|url
Retrieving properties along the nested query:
/?query=posts.id|title|url|comments.id|content|date|author.id|name|url|posts.id|title|url
Field arguments:
/?query=posts(searchfor:template,limit:3).id|title
Variables:
/?query=posts(searchfor:$search,limit:$limit).id|title&limit=3&search=template
or:
/?query=posts(searchfor:$search,limit:$limit).id|title&variables[limit]=3&variables[search]=template
Aliases:
/?query=posts(searchfor:template,limit:3)@searchposts.id|title
Bookmarks: (to return to some query path, to keep adding data)
/?query=posts(searchfor:template,limit:3)[searchposts].id|title,[searchposts].author.id|name
Bookmark + Alias:
/?query=posts(searchfor:template,limit:3)[@searchposts].id|title,[searchposts].author.id|name
Fragments:
/?query=posts(limit:3).--postProps,posts(limit:4).author.posts.--postProps&postProps=id|title|url
Or:
Directives:
Include:
/?query=posts.id|title|url<include(if:$include)>&variables[include]=true
/?query=posts.id|title|url<include(if:$include)>&variables[include]=
Skip:
/?query=posts.id|title|url<skip(if:$skip)>&variables[skip]=true
/?query=posts.id|title|url<skip(if:$skip)>&variables[skip]=
The different elements can be included within the other elements in a straightforward manner:
Concatenating fragments:
/?query=posts.--fr1.--fr2&fragments[fr1]=author.posts(limit:1)&fragments[fr2]=id|title
Fragments inside fragments:
/?query=posts.--fr1.--fr2&fragments[fr1]=author.posts(limit:1)&fragments[fr2]=id|title|--fr3&fragments[fr3]=author.id|url
Fragments with aliases:
/?query=posts.--fr1.--fr2&fragments[fr1]=author.posts(limit:1)@firstpost&fragments[fr2]=id|title
Fragments with variables:
/?query=posts.--fr1.--fr2&fragments[fr1]=author.posts(limit:$limit)&fragments[fr2]=id|title&variables[limit]=1
Fragments with directives:
/?query=posts.id|--props<include(if:hasComments())>&fragments[props]=title|url<include(if:not(hasComments()))>
Fragments with "Skip output if null":
/?query=posts.id|--props?&fragments[props]=title|url|featuredimage
Since we are creating a new syntax, why stop in what already exists? We are creating, we are dreaming, let's also build what doesn't exist yet! The following features below are not part of GraphQL, but sure they should be!
Operators:
/?query=not(true)
/?query=or([1, 0])
/?query=and([1, 0])
/?query=if(true,Show this text,Hide this text)
/?query=equals(first text, second text)
/?query=isNull(),isNull(something)
/?query=sprintf(API %s is %s, [PoP, cool]))
Helpers:
/?query=context
/?query=var(route),var(target)@target,var(datastructure)
Composable fields:
/?query=posts.hasComments|not(hasComments())
/?query=posts.hasComments|hasFeaturedImage|or([hasComments(),hasFeaturedImage()])
/?query=var(fetching-site),posts.hasFeaturedImage|and([hasFeaturedImage(), var(fetching-site)])
/?query=posts.if(hasComments(),sprintf(Post with title '%s' has %s comments,[title(), commentsCount()]),sprintf(Post with ID %s was created on %s, [id(),date(d/m/Y)]))@postDesc
/?query=users.name|equals(name(), leo)
/?query=posts.featuredimage|isNull(featuredimage())
Composable fields with directives:
/?query=posts.id|title|featuredimage<include(if:not(isNull(featuredimage())))>.id|src
/?query=posts.id|title|featuredimage<skip(if:isNull(featuredimage()))>.id|src
Skip output if null:
/?query=posts.id|title|featuredimage?.id|src
🦸🏻
That seems promising, right!? What do you think? If you like it, check the repo for more info.
Thanks for reading!
]]>
I just applied to speak in ConFoo, a developer-oriented, French/English conference taking place in Montreal in February 26-28, 2020. Since I've never been to Canada but I would really love to, I gave it my very best: I submitted 9 talks on topics that I work with, and for which I'm currently writing several articles for Smashing Magazine and creating a few WordPress plugins (both of these to see the light of the day soon! 😃):
If you'd like to vote for me, this is the link (you need to create a user account though). More than appreciated! ❤️
My proposed talks are the following ones:
1. The greatest breakthrough for developers: “Serverless” PHP
“Serverless” PHP will quite likely become the next compelling stack, since it enables the creation of apps which are both static and dynamic at the same time: The same code can pre-render the site into static HTML (to upload to CDN) and serve dynamic functionality (logging in, sending emails, adding comments). The JAMstack won't be able to compete with this developer convenience!
Let's explore how this paradigm can become the new game changer.
2. The (Upcoming) PHP Renaissance
PHP has been increasingly facing competition from JavaScript to build modern websites, since this language provides dynamic features that server-side languages cannot match.
However, the future for PHP is bright: Both PHP the language, and the PHP ecosystem, keep developing at a great speed and offering improvements that continuously take it to the next level.
In this presentation, we will discover PHP's cards to lure developers back.
3. Revising GraphQL: Everything is a Component (not a Graph!)
GraphQL's architecture is its biggest liability, since it gives raise to issues which, after several years of trying, nobody has been able to solve (complex security, lack of server-side caching, difficulty of collaboration among team members, and a few others).
Luckily, there is a similar approach to graphs for representing information, which does not suffer any of its disadvantages: Components!
Let's explore how components can save the day.
4. Choosing between REST and GraphQL? You can have both!
GraphQL is on the rise due to its great development experience and performance, however REST has sturdy features that we wouldn't want to do away with (server-side caching, better security, and others). Since each API has trade-offs, we need to decide which API is more relevant to our project.
Fortunately, a new approach to building APIs provides the benefits of both these APIs, at the same time! Let's learn all about it in this presentation.
5. How WordPress may come to dominate management of all content
Through Gutenberg and the concept of blocks, WordPress has the chance to become the Content Management System of choice for managing not just content for the web, but also content for other platforms (such as email and mobile apps) and other types of digital assets (such as videos and images).
Let's explore how Gutenberg may create a brand-new user experience concerning the creation, edition and managing of content in the years to come.
6. Bringing the back of the front-end back to the back-end
Thanks to the success of components, many responsibilities which used to be tackled in the back-end (site-level architecture, routing, state management) are now implemented in the front-end. As a result, the front-end can now be divided into the “back of the front-end” and the “front of the front-end”.
The concept of components is now supported in the back-end too, enabling all the shifted tasks to be dealt with in the server-side once again.
7. Using a component-model to build a site in PHP
Front-end developers love building websites using components, as evidenced by the growing popularity of libraries such as React and Vue.js. And back-end developers? Until recently, component-driven design (i.e. the ability to create sites through components as building units) was available only through front-end coding...
But this is not the case anymore: a new PHP library enables to create websites using components as building blocks in PHP.
8. Building a CMS-agnostic site in PHP
Deciding which framework to use for a project can be difficult. But then there is a better option: Using code that can work on top of whichever CMS or framework, and can switch from one to another with the minimum possible effort.
This talk will explain how to implement such architecture, and demonstrate an application which can run on WordPress, Laravel and Symfony.
9. Implementing the "Create Once, Publish Everywhere" strategy
COPE (Create Once, Publish Everywhere) is a technique which allows to publish content across different platforms such as web, email, app, and others. It achieves its goal by decoupling the meaning and presentation layers of the content.
We will learn how to implement COPE through a block-based architecture (as compared to the blob-based architecture), which allows us to manage chunks of content individually and extract their metadata.

Vapor relies completely on the AWS cloud. By integrating Laravel and AWS, Vapor enables to deploy Laravel applications to the cloud with the following benefits:
From all of these, the one benefit that most resonates with me is letting go of the server. Managing servers has time and again proved difficult, requiring fine tuning between the incoming traffic, server power and money to spend on it. Even though the AWS cloud allows for autoscaling, sometimes even the lowest viable unit to provision for production, such as an AWS EC2 small instance, may prove too much power for the requirements of the application. (From my experience, micro and nano instances are not fully reliable, since they soon run out of steam and must be restarted, and the small instance may be too expensive for my needs. For instance, I'm currently hosting a demo of the PoP API in its own server, under https://newapi.getpop.org, and its monthly cost is not negligible).
Until today there was no way around this issue for PHP. Hence the recent total victory of the JAMstack: Since it is composed of static files (HTML/JS/CSS), you can host your website directly on the cloud. Not only its speed is incredibly fast, but also, through Netlify, it is free! How could PHP beat that? Well, it couldn't!
That is until now. What Taylor Otwell seems to have achieved is to execute PHP code through the "serverless" architecture. Then, we can simply push our code to a GitHub repo, and through continuous integration it will execute a command to deploy the PHP application to the cloud. In Vapor, currently, assets are uploaded to the CDN and PHP code is executed as serverless functions. However, it is not difficult to create a PHP application that can be pre-rendered as static HTML files which, together with the assets (JS/CSS), is uploaded to the CDN, and the dynamic portion of the application (such as the user log in, sending emails, adding comments, etc) is taken care of by serverless functions running PHP code. The beauty of this scheme is that it will be as fast as the JAMstack, since the application is also deployed to a CDN, however it also supports dynamic functionality as part of the application itself! Then, we need to code only one single application in PHP that has both static and dynamic behaviour. A very simple stack. One single technology to learn. All the power from PHP. How can you possibly beat that? You can't!
This is what I call the JAMPstack: JAMstack + PHP.
I must emphasize this: the JAMstack will be no match for JAMPstack, because it is much more complex (usually composed of several moving parts, interacting with each other) and more disconnected (different services each holding different pieces of content cannot produce the same functionality as when all content is centralized). For instance, nobody has provided a proper solution for comments in the JAMstack: The Netlify solution is to store comments in all-purpose forms, which doesn't allow comments to have more than one level of depth; another solution is to save comments as markdown files inside the repo, however its execution takes ages, making the experience for the user who wrote the comment and is waiting for feedback far from optimal. The JAMPstack will deliver all the expected JAMstack behaviour, plus providing the usual advantages of executing "server-side" code to support dynamic functionality.
(The other victory of the JAMstack belongs to JavaScript, because it supports the concept of "components", as provided by libraries React and Vue, creating a wonderful development experience. However, my own project PoP provides an implementation of components for the back-end, which I'm still working on but should soon be ready, enabling PHP to have support for components too.)
PHP is not necessarily in decline, since it still is the most widespread language powering the web. However, it has for a few years now lost its attraction for developers, who were jumping in droves to the JavaScript side, attracted by the convenience of the JAMstack. Now, we can claim those developers back to the back-end, and PHP can become a top language of choice for the development world, once again! Isn't that a fascinating thought?
So far, so good. However, there is one caveat (at least for me): I'm most interested in WordPress, and even though doing the jump to Laravel is extremely attractive, I believe that this solution would make the most impact if it could support WordPress. Imagine 1/3rd of the web suddenly becoming "serverless"... Wouldn't that be amazing?
Now, I have no clue if WordPress could be ported into the serverless architecture. Laravel truly seems to be ahead of the curve, planning its next move way before anyone else, so this new feature follows as a consequence from all the previous features they implemented: For instance, Laravel natively supports queues, which play an important role in the serverless architecture, and which WordPress does not currently natively support. Hence, right now porting WordPress to something similar to Laravel Vapor is a big if. Can it be done? Would it be feasible, even if not all features can be supported? Would it even make sense? I have no response to all of these questions.
However, good news is that Laravel Vapor is open source. So the task at hand would not start from scratch: We can evaluate how Taylor built his solution, and analyze if it can be ported to WordPress, how easily of difficult it would be to do. Doesn't this seem like a wonderful task to work on?
So, here is my proposal: If you are reading this, and you feel excited by this prospect, then let's do it! If you are a developer keen to join, please let me know in this Twitter thread (comments are still not enabled in my JAMstack blog 😂). If you're an investor eager to find a new exciting venture, and would be willing to fund this project, please send me a DM.
Please spread the word 🙏. Thanks for reading!
I just found a tool that enables to read the WordPress database from within Laravel: Corcel. Then, we can create an application based on a stack including both WordPress and Laravel:
This is a beautiful stack, which obtains the best of both worlds: Great content creation through Gutenberg, while removing the need to provision/maintain servers through Laravel Vapor. 😺
Carl Alexander was equally impacted as I was when watching Taylor Otwell's presentation. But while I merely talked about it, he actually decided to build a serverless WordPress solution.
This is how his project, Ymir, looks so far:
Let's hope he finishes it soon!
I have officially added the serverless API for WordPress to the roadmap for GraphQL by PoP (my GraphQL server in PHP).
Of course, this doesn't solve serverless for WordPress in general, only for requesting data from WordPress through an API. But this is already quite awesome, since we could then use WordPress as the CMS to manage the data, spinning its server only when we need to create/update the data, and provide the data to whichever client or application needs it through serverless.
This is WordPress as a CMS without hosting! (Well, we still need a server for the database, but that's unavoidable)
]]>
The plugin is called Block Metadata, and its use case is very simple: it extracts all the metadata for all the blocks inside of a blog post, converting this metadata into a medium-agnostic format.
The plugin's goal is to implement the Create Once, Publish Everywhere strategy (alias COPE), enabling to have our Gutenberg-edited blog post become the single source of truth for all content, for all different mediums or platforms: web, email/newsletters, iOS/Android apps, home assistants (like Amazon Alexa), car-entertainment systems, and so on.

I learnt about the COPE concept several years ago, watching Karen McGrane's talk Content in a Zombie Apocalypse. However, only now this strategy is easily implementable, thanks to Gutenberg. Or, to be more precise, thanks to the block-based architecture of Gutenberg. (Actually, Gutenberg could provide a better support for COPE making it more performant, but the current implementation still works fairly well.)
The plugin provides a REST API endpoint, /wp-json/block-metadata/v1/metadata/{POST_ID}, which transforms the Gutenberg blog post content, from this:
<!-- wp:block {"ref":1500} /-->
<!-- wp:image {"id":262,"sizeSlug":"large"} -->
<figure class="wp-block-image size-large"><img src="https://ps.w.org/gutenberg/assets/banner-1544x500.jpg" alt="" class="wp-image-262"/></figure>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p><em>Etiam tempor orci eu lobortis elementum nibh tellus molestie. Neque egestas congue quisque egestas. Egestas integer eget aliquet nibh praesent tristique. Vulputate mi sit amet mauris. Sodales neque sodales ut etiam sit. Dignissim suspendisse in est ante in. Volutpat commodo sed egestas egestas. Felis donec et odio pellentesque diam. Pharetra vel turpis nunc eget lorem dolor sed viverra. Porta nibh venenatis cras sed felis eget. Aliquam ultrices sagittis orci a. Dignissim diam quis enim lobortis. Aliquet porttitor lacus luctus accumsan. Dignissim convallis aenean et tortor at risus viverra adipiscing at.</em></p>
<!-- /wp:paragraph -->
<!-- wp:core-embed/youtube {"url":"https://www.youtube.com/watch?v=9pT-q0SSYow","type":"video","providerNameSlug":"youtube","className":"wp-embed-aspect-16-9 wp-has-aspect-ratio"} -->
<figure class="wp-block-embed-youtube wp-block-embed is-type-video is-provider-youtube wp-embed-aspect-16-9 wp-has-aspect-ratio"><div class="wp-block-embed__wrapper">
https://www.youtube.com/watch?v=9pT-q0SSYow
</div><figcaption><strong>This is the video caption</strong></figcaption></figure>
<!-- /wp:core-embed/youtube -->
<!-- wp:columns -->
<div class="wp-block-columns"><!-- wp:column -->
<div class="wp-block-column"><!-- wp:quote -->
<blockquote class="wp-block-quote"><p>Saramago sonogo</p><p>En la lista del longo</p><cite><em><a href="https://yahoo.com">alguno</a></em></cite></blockquote>
<!-- /wp:quote --></div>
<!-- /wp:column -->
<!-- wp:column -->
<div class="wp-block-column"><!-- wp:image {"id":70,"sizeSlug":"large"} -->
<figure class="wp-block-image size-large"><img src="https://ps.w.org/gutenberg/assets/banner-1544x500.jpg" alt="" class="wp-image-70"/></figure>
<!-- /wp:image --></div>
<!-- /wp:column --></div>
<!-- /wp:columns -->
<!-- wp:heading -->
<h2>Some heading here</h2>
<!-- /wp:heading -->
<!-- wp:gallery {"ids":[1502,1505,1503,1504]} -->
<ul class="wp-block-gallery columns-3 is-cropped"><li class="blocks-gallery-item"><figure><img src="https://newapi.getpop.org/wp/wp-content/uploads/2019/08/Sample-jpg-image-50kb.jpg" alt="" data-id="1502" data-link="https://newapi.getpop.org/uncategorized/cope-with-wordpress-post-demo-containing-plenty-of-blocks/attachment/sample-jpg-image-50kb/" class="wp-image-1502"/><figcaption>Caption 1st image</figcaption></figure></li><li class="blocks-gallery-item"><figure><img src="https://newapi.getpop.org/wp/wp-content/uploads/2019/08/setting-rest-fields-1024x145.png" alt="" data-id="1505" data-link="https://newapi.getpop.org/uncategorized/cope-with-wordpress-post-demo-containing-plenty-of-blocks/attachment/setting-rest-fields/" class="wp-image-1505"/></figure></li><li class="blocks-gallery-item"><figure><img src="https://newapi.getpop.org/wp/wp-content/uploads/2019/08/Sample-jpg-image-100kb.jpg" alt="" data-id="1503" data-link="https://newapi.getpop.org/uncategorized/cope-with-wordpress-post-demo-containing-plenty-of-blocks/attachment/sample-jpg-image-100kb/" class="wp-image-1503"/><figcaption>Caption 3rd image</figcaption></figure></li><li class="blocks-gallery-item"><figure><img src="https://newapi.getpop.org/wp/wp-content/uploads/2019/08/banner-1544x500-1024x332.jpg" alt="" data-id="1504" data-link="https://newapi.getpop.org/uncategorized/cope-with-wordpress-post-demo-containing-plenty-of-blocks/attachment/banner-1544x500/" class="wp-image-1504"/><figcaption>Final <strong>caption</strong> <a href="https://getpop.org">for all</a></figcaption></figure></li></ul>
<!-- /wp:gallery -->Into this:
[
{
"blockName": "core/paragraph",
"meta": {
"content": "Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Dolor sed viverra ipsum nunc aliquet bibendum enim. In massa tempor nec feugiat. Nunc aliquet bibendum enim facilisis gravida. Nisl nunc mi ipsum faucibus vitae aliquet nec ullamcorper. Amet luctus venenatis lectus magna fringilla. Volutpat maecenas volutpat blandit aliquam etiam erat velit scelerisque in. Egestas egestas fringilla phasellus faucibus scelerisque eleifend. Sagittis orci a scelerisque purus semper eget duis. Nulla pharetra diam sit amet nisl suscipit. Sed adipiscing diam donec adipiscing tristique risus nec feugiat in. Fusce ut placerat orci nulla. Pharetra vel turpis nunc eget lorem dolor. Tristique senectus et netus et malesuada."
}
},
{
"blockName": "core/image",
"meta": {
"src": "https://ps.w.org/gutenberg/assets/banner-1544x500.jpg"
}
},
{
"blockName": "core/paragraph",
"meta": {
"content": "<em>Etiam tempor orci eu lobortis elementum nibh tellus molestie. Neque egestas congue quisque egestas. Egestas integer eget aliquet nibh praesent tristique. Vulputate mi sit amet mauris. Sodales neque sodales ut etiam sit. Dignissim suspendisse in est ante in. Volutpat commodo sed egestas egestas. Felis donec et odio pellentesque diam. Pharetra vel turpis nunc eget lorem dolor sed viverra. Porta nibh venenatis cras sed felis eget. Aliquam ultrices sagittis orci a. Dignissim diam quis enim lobortis. Aliquet porttitor lacus luctus accumsan. Dignissim convallis aenean et tortor at risus viverra adipiscing at.</em>"
}
},
{
"blockName": "core-embed/youtube",
"meta": {
"url": "https://www.youtube.com/watch?v=9pT-q0SSYow",
"caption": "<strong>This is the video caption</strong>"
}
},
{
"blockName": "core/quote",
"meta": {
"quote": "Saramago sonogo\\nEn la lista del longo",
"cite": "<em>alguno</em>"
}
},
{
"blockName": "core/image",
"meta": {
"src": "https://ps.w.org/gutenberg/assets/banner-1544x500.jpg"
}
},
{
"blockName": "core/heading",
"meta": {
"size": "xl",
"heading": "Some heading here"
}
},
{
"blockName": "core/gallery",
"meta": {
"imgs": [
{
"src": "https://newapi.getpop.org/wp/wp-content/uploads/2019/08/Sample-jpg-image-50kb.jpg",
"width": 300,
"height": 300
},
{
"src": "https://newapi.getpop.org/wp/wp-content/uploads/2019/08/setting-rest-fields.png",
"width": 1738,
"height": 246
},
{
"src": "https://newapi.getpop.org/wp/wp-content/uploads/2019/08/Sample-jpg-image-100kb.jpg",
"width": 689,
"height": 689
},
{
"src": "https://newapi.getpop.org/wp/wp-content/uploads/2019/08/banner-1544x500.jpg",
"width": 1544,
"height": 500
}
]
}
}
}Notice how different block types have different properties extracted from them:
To see it working live, check out these links: a random blog post (with plenty of Gutenberg blocks in it), its data added by Gutenberg on each block in the post, and, finally, its extracted medium-agnostic metadata, listing properties on a block-by-block basis.
There is more information on how it works on the slides from my presentation COPE with WordPress @ WordCamp Singapore 2019 from last week (source):
And the video with the talk is now available too:
If you install the plugin and find any problem, please let me know and I'll fix it. If you use it and find it useful, let me know and I'll celebrate! 🥳
How so quick? It's not due to magic, even though it feels like it. It's all because of Hylia, a starter kit for static site generator Eleventy and readily deployable to Netlify. The site you're currently browsing is simply a fork of the Hylia repo, customized with my own colors and a few other modifications here and there. And even though I'm terrible at design (CSS is not my forte), it looks quite neat!
I chose Hylia for two main reasons (excluding the fact that it is open source 😀❤️): because it is extremely quick to set-up (as I just mentioned) and extremely powerful. Indeed, watching the site be compiled automatically whenever I press "Ctrl + S" in VSCode, deployed to my localhost, and hot reloaded in the browser, is a breathtaking experience. I love it!
The other motivation is the JAMstack: whichever framework/technology/language I chose for my own blog, I wanted it to be based on a static site generator, so my site could benefit from the speed of being accessed straight from a CDN (and Netlify provides the hosting for free!). I have considered also using Hugo and Gatsby, and even though Eleventy won the first battle, I still plan to go back to them at some point, maybe for some other project.
Finally, Hylia stands out not only in its present but also, hopefully, in its future: its roadmap delineates the addition of Webmentions (to be part of the IndieWeb, yay!) and comments already integrated with Netlify forms.
(Unfortunately, comments in the JAMstack seem to be a thorny issue that nobody has successfully solved to date. For instance, storing comments in all-purpose forms is not an ideal solution, since then comments have only one level of depth. However, this solution is still better than no comments at all, so I welcome it until somebody implements something more appropriate).
In the IndieWeb there's the concept of selfdogfooding: If you are implementing some functionality, you yourself must be using it, in your own website. Otherwise, how can you possibly convince others to use it, when it doesn't even convince or suit you? (This way of thinking is related to the "you must do what you preach" philosophy.)
")
I fully believe in this premise, and I attempt to adhere to it as much as possible. In this case, I am the creator of PoP, an API + component model + framework for building sites in PHP, and, of course, I should be using PoP for building my own blog! (fortunately, PoP also can export the site as static to have it deployed on a CDN). However, PoP is not ready for building sites yet (only the API-building functionality has been finished; site-building comes next), and it has not been for a couple of years. Hence my delay!
A few months ago I decided that enough is enough, that I should implement my blog no matter how, and once PoP is ready, then migrate it. My current blog is, then, only temporary (maybe between 6 months and 1 year). Common sense would dictate that I couldn't use a complex framework that takes plenty of time to set-up, code and deploy. And that's why Hylia, with its simplicity yet great power, has been a great choice 🤘🏽. Thanks Andy!
]]>That's me presenting, via #WordCampSG:
.@losoviz presenting a paradigm shift in how to think about content at #WordCampSG pic.twitter.com/gr7CJIjXsb
— David Wang (@blogjunkie) August 16, 2019
These are the slides:
If you are in the conference right now, and you're interested in the topic, let's talk!
]]>(Btw, PoP's migration to Composer is still ongoing. If you are willing to become involved, it will be greatly appreciated 😀❤️.)
However, not everything in Composer shines. In particular, because Composer updates its package directory every 10 minutes or so, it can take a while to be able to update our projects using the latest version of our code (even if it is already available on the Git repo). In particular, when we are developing a functionality and we want to have another package use it, to test it, then waiting these 10 minutes can be very annoying. Too bad!
But there is some kind of solution, though. If your code is using the PSR-4 (or PSR-0) autoloading feature (which it should!), then your composer.json file will have a section like this:
{
...
"autoload": {
"psr-4": {
"{YOUR_VENDOR_NAME}\\{YOUR_PACKAGE_NAME}\\": "src"
}
}
...
}This line indicates where to find the source code for a given namespace. For instance, for package PoP Engine, the configuration is like this:
{
...
"autoload": {
"psr-4": {
"PoP\\Engine\\": "src"
}
}
...
}Then, whenever the code references class PoP\Engine\Component, Composer attempts to load file Component.php located under the src/ folder from package PoP Engine (which serves namespace PoP\Engine).
We can hack into this configuration, by overriding the folders for all the packages to test, pointing them to a folder in our local drive where the recently-developed code is. This way, Composer will load the file directly from the development folder, instead of using the version downloaded from the packagist.org directory.
For instance, a project "My Project" (stored in local folder ~/GitHub-Projects/my-project/) depending on package "PoP Engine" (stored in local folder ~/GitHub-Libraries/getpop/engine/) can immediately test its code by adding this configuration on the project's composer.json file:
{
...
"autoload": {
"psr-4": {
"PoP\\Engine\\": "../GitHub-Libraries/getpop/engine/src"
}
}
...
}And then regenerating Composer's autoloader file:
$ composer dumpautoloadAnd voilà, no more waiting!
]]>wp-config.php to enter the database configuration and other variables during the installation process (more info on this on my previous blog post). This is achieved through WP-CLI, a tool which provides commands to interact with WordPress directly from the command line (or through a script), allowing us to not have to log into the wp-admin anymore. It is so convenient!
What the script does is to take the required configuration values from environment variables (which must be set in advance) and then, dynamically, create file wp-config.php. Hence, we can install the project directly from our repository, and a unique repo can serve all of our environments (DEV, STAGING, PROD). Preferably, our repos must never contain environment information! This is one of the fundamental practices of the Twelve Factor App, which defines guidelines to make application deployments simpler, faster and more scalable.
To dynamically save the environment variable values in file wp-config.php the script uses the following WP-CLI command:
wp config set {constant_name} {constant_value}Then, to fill in the database information, the user is required to set the following environment variables:
$ export DB_NAME={SITE_DB_NAME}
$ export DB_USER={SITE_DB_USER}
$ export DB_PASSWORD={SITE_DB_PASSWORD}
$ export DB_HOST={SITE_DB_HOST}To add these values to file wp-config.php, the script executes:
wp config set DB_NAME $DB_NAME
wp config set DB_USER $DB_USER
wp config set DB_PASSWORD $DB_PASSWORD
if [ -n "$DB_HOST" ]
then
wp config set DB_HOST $DB_HOST
fiThe host information is optional, because by default it is set as "localhost" which is an acceptable value. Hence, the script must check if environment variable $DB_HOST was set or not. It does this through a bash script conditional, if [ -n "$DB_HOST" ] then ... fi, which means: if variable $DB_HOST is not empty, then execute the instructions between then and fi.
All other environment variables are mandatory, so the script must also validate that they have been set. It does this through the following bash script commands:
#!/bin/bash
# Flag to know if there are errors
ERROR_ENV_VARS=""
# Required for wp-config.php
if [ -z "$DB_NAME" ]
then
ERROR_ENV_VARS="$ERROR_ENV_VARS\nDB_NAME"
fi
if [ -z "$DB_USER" ]
then
ERROR_ENV_VARS="$ERROR_ENV_VARS\nDB_USER"
fi
if [ -z "$DB_PASSWORD" ]
then
ERROR_ENV_VARS="$ERROR_ENV_VARS\nDB_PASSWORD"
fi
# If there are errors, return an error state
if [ -n "$ERROR_ENV_VARS" ]
then
echo "Fatal error: The following environment variable(s) cannot be empty: $ERROR_ENV_VARS"
echo "Terminating process."
exit 1
fiNotice the exit 1 at the end of the script? Through that command, the script is interrupted (after displaying an error on the console) and it doesn't proceed to install WordPress.
To set the SALT keys we can also define environment constant for each of them, or ask WP-CLI to create and assign random values:
wp config shuffle-saltsAnd that's it! With a few bash script commands we are able to automate the whole WordPress installation process. Now, after the user enters the environment information, all that is needed is to execute:
$ composer create-project leoloso/wp-installAnd voilà! A new WordPress site will be happily installed!
]]>wp-config.php, install the WordPress database and manually change the site URL in wp-admin. One reader asked, through a comment, if it was possible to also automate this step through WP-CLI, the command-line interface for WordPress, and I was not so sure about it, since I had never tried.
Well, now I have tried, and I can say: Yes, it is possible. Moreover, to prove it, I have created a Composer project executing the missing extra steps through WP-CLI, and it works like a charm! Now, I can simply execute a simple command, and my WordPress instance will be installed in a matter of minutes, without any further intervention. I put all the code in this GitHub repo: Install WordPress through Composer and WP-CLI.
If you need to quickly install WordPress, try out this project and let me know how it went. Enjoy!
]]>I will be blogging about those small things that I encounter every day when coding on PoP, attending events, working on random projects, reading a book, or anything that is noteworthy. I hope you enjoy it!
")